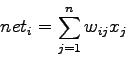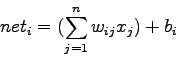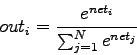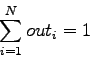Next: 2.2.2 Addestramento Up: 2.2 Funzionamento di una Previous: 2.2 Funzionamento di una Index
Il loro funzionamento è altamente parallelizzabile, infatti sono composte da numerose unità elementari il cui funzionamento è molto semplice. Ogni neurone artificiale esegue la somma degli input pesati con il valore delle interconessioni, per poi farne una trasformazione con una funzione spesso non lineare. Uno degli aspetti più interessanti è che una rete neurale non viene progettata per compiere una particolare attività, ma viene addestrata, con una serie di esempi, tramite un algoritmo di apprendimento automantico.
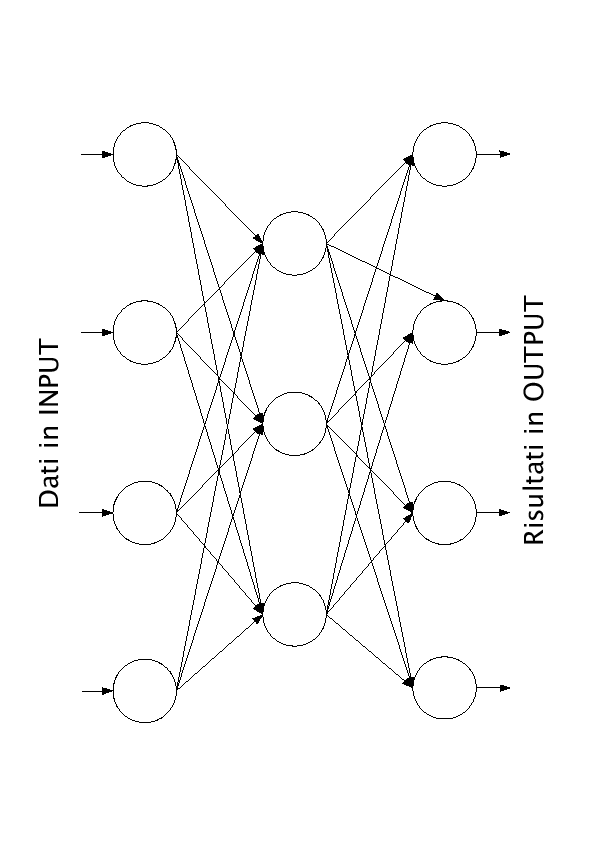
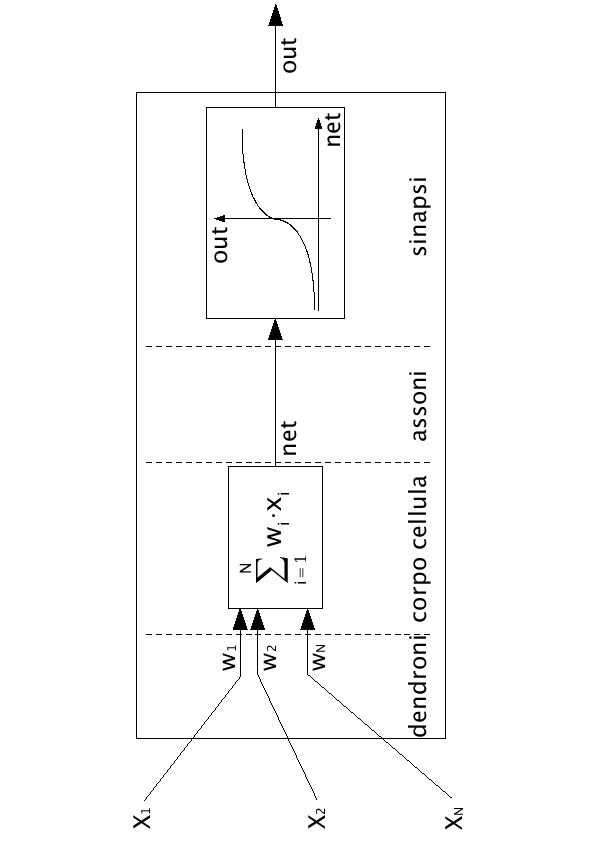
Questa qualità ne consente l'applicazione in svariati campi quali l'intelligenza artificiale, il trattamento dei segnali (voce, immagini, etc.), il controllo di robot o di processi industriali o la soluzione di problemi complessi raggiungendo, in molti casi, le prestazioni di altre tecniche più complesse e piú difficili da progettare. Nel corso degli anni si sono sperimentate diverse strutture, tra cui quella in assoluto più utilizzata è quella di tipo feed-forward, di solito con più strati (figura 2.2).Andando ad analizzare più in dettaglio la struttura di un singolo neurone possiamo concettualmente dividerlo negli ingressi, nei pesi (dendriti), nel corpo (cellula) e in una funzione di uscita (sinapsi) (figura 2.3). I pesi saranno i responsabili, assieme al tipo di funzione di uscita, del comportamento del singolo neurone e della rete in generale. Saranno loro che dovranno essere correttamente modificati in fase di addestramento, al fine di garantire un comportamento corretto al modello.
Definito per ogni singola unità ![]() un vettore di ingresso
un vettore di ingresso
![]() e un vettore di pesi
e un vettore di pesi
![]() , il corpo del neurone compie una somma pesata degli ingressi:
, il corpo del neurone compie una somma pesata degli ingressi:
Tra i pesi ne esiste uno speciale che prende il nome di bias . Esso non è legato a nessun'altra unità della rete ed è come se avesse ingresso sempre uguale a 1. Il bias serve a far compiere una traslazione sull'asse delle ascisse alla funzione di uscita. I nuovi ingressi prenderanno perciò la forma
![]() e nel vettore dei pesi sarà presente un elemento addizionale
e nel vettore dei pesi sarà presente un elemento addizionale ![]() che rappresentera il peso riferito al bias
che rappresentera il peso riferito al bias
![]() . L'equazione (2.1) prenderà perciò la forma:
. L'equazione (2.1) prenderà perciò la forma:
Al valore ![]() viene poi applicata una trasformazione al fine di generare l'uscita
viene poi applicata una trasformazione al fine di generare l'uscita ![]() . Le più comuni sono la funzione sigmoide, la funzione gradino, la funzione lineare, la funzione tangente iperbolica e la funzione segno, anche se quella più utilizzata in assoluto è la funzione sigmoide:
. Le più comuni sono la funzione sigmoide, la funzione gradino, la funzione lineare, la funzione tangente iperbolica e la funzione segno, anche se quella più utilizzata in assoluto è la funzione sigmoide:
A questo punto il funzionamento della rete neurale può essere spiegato senza difficoltà. La rete è semplicemente formata da un insieme di unità elementari. Quando arriva un nuovo segnale da analizzare esso viene caricato nei dati di input del primo livello di neuroni i quali, tramite (2.2) e (2.3) generano un output. Questo risultato, assieme all'uscita dei neuroni dello stesso livello, costituirà un nuovo input per le unità al livello superiore. Il processo sarà così iterato fino all'ultimo livello in cui si otterrà la probabilità per ogni singlo output.
Nella realtà è tutto un po' più complicato, nell'ultimo livello di una rete neurale di tipo feed-forward si utilizza di solito la funzione softmax. Essa è utile tutte le volte in cui si vuole interpretare l'output di una rete come una probabilità a posteriori. Dato ![]() ,
,
![]() , dove
, dove ![]() rappresenta il numero di output della rete e
rappresenta il numero di output della rete e ![]() è il valore ottenuto da (2.2), la funzione softmax si scrive come:
è il valore ottenuto da (2.2), la funzione softmax si scrive come:
con:
Una volta capito il funzionamento, l'aspetto più importante e difficile da affrontare consiste nel addestramento della rete: nel cercare cioè i pesi e i bias che le permettano di essere il più possibile aderente al fenomeno che deve modellare.
Stefano Scanzio 2007-10-16