Next: 5.1.3 Output Layer Adaptation Up: 5.1 Descrizione delle tecniche Previous: 5.1.1 Linear Input Network Index
Ogni pattern di ingresso è composto da 7 blocchi da 39 unità con la stessa struttura e le stesse grandezze rappresentate: ![]() ,
, ![]() ,
, ![]() ,
,
![]() ,
, ![]() ,
,
![]() .
La differenza tra i 7 blocchi consiste nel fatto che i primi tre rappresentano il contesto sinistro, il quarto il contesto centrale e gli ultimi tre quello destro.
Questo uguaglianza tra i blocchi ha permesso la separazione in 7 gruppi da 39 elementi, utilizzata per la LIN in sezione (5.1.1).
Nell'adattamento al parlatore la LIN ha solo lo scopo di raccogliere le informazioni specifiche del parlatore, nel caso della LIN di sezione (5.1.1) essa tiene traccia di queste caratteristiche in 7 blocchi separati, riferiti ai 7 contesti. Questa ripetizione di informazioni fornisce risultati migliori perché aiuta globalmente la rete a riconoscere meglio, ma non porta nessuna conoscenza in più sul parlatore.
.
La differenza tra i 7 blocchi consiste nel fatto che i primi tre rappresentano il contesto sinistro, il quarto il contesto centrale e gli ultimi tre quello destro.
Questo uguaglianza tra i blocchi ha permesso la separazione in 7 gruppi da 39 elementi, utilizzata per la LIN in sezione (5.1.1).
Nell'adattamento al parlatore la LIN ha solo lo scopo di raccogliere le informazioni specifiche del parlatore, nel caso della LIN di sezione (5.1.1) essa tiene traccia di queste caratteristiche in 7 blocchi separati, riferiti ai 7 contesti. Questa ripetizione di informazioni fornisce risultati migliori perché aiuta globalmente la rete a riconoscere meglio, ma non porta nessuna conoscenza in più sul parlatore.
L'idea della Joint Linear Input Network (J-LIN) è quello di legare i 7 blocchi in uno solo, riducendo il numero di pesi da addestrare a 1560.
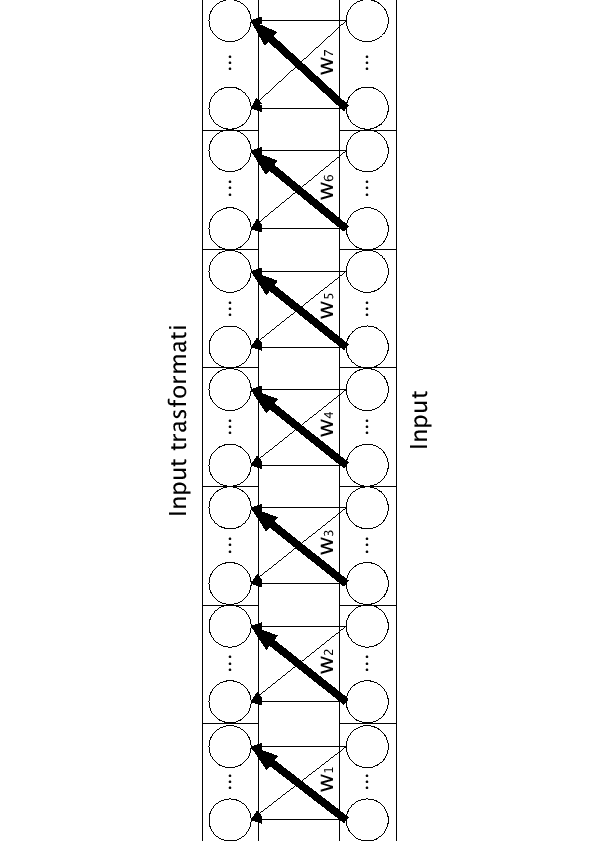
Per relizzare una J-LIN si è deciso di legare i pesi dei 7 archi che, blocco per blocco, occupano la stessa posizione. Costringendoli ad avere lo stesso valore si può memorizzare solo uno di essi, riducendo di 7 volte la dimensione del file dei pesi per la rete.
L'unico cosa ancora da analizzare rimane come modificare i pesi della rete durante il training. Per fra ciò analizziamo il comportamento di un qualsiasi peso della rete. Sia ![]() il peso preso in considerazione, esso avrà altri 6 pesi legati, uguali, che saranno
il peso preso in considerazione, esso avrà altri 6 pesi legati, uguali, che saranno ![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
, ![]() e
e ![]() (figura 5.3).
(figura 5.3).
| (5.3) |