Next: 7.3 Conclusioni Up: 7.2 Esperimenti effettuati Previous: 7.2.1 Esperimenti compiuti sul Index
In TIMIT sono presenti 10 frasi per ogni parlatore, da cui sono state eliminate le 2 frasi di tipo SA di origine dialettale. L'esperimento è stato compiuto adattando i modelli SD con la prima frase di ognuno dei 168 parlatori di test. Le rimanenti 7 frasi di test di ogni parlatore, sono state utilizzate per ricavare la percentuale di riconoscimento al variare del coefficiente di interpolazione.
Il modello AD è stato addestrato in modo migliore rispetto a quanto avvenuto per l'italiano, in cui erano presenti solamente 4 parlatori. Per addestrarlo si sono utilizzate tutte le frasi di training del database inglese, ad eccezione di quelle di tipo SA, per un totale di 3696 frasi suddivise in 462 parlatori e 10 epoche di addestramento.
Gli esperimenti sono stati eseguiti con 1 e 10 epoche di addestramento dei modelli SD, eseguendo l'interpolazione di tutta la rete e di J-LIN. LIN non è stata analizzata, perchè i suoi risultati sono inferiori rispetto alle prestazioni delle altre due tecniche.
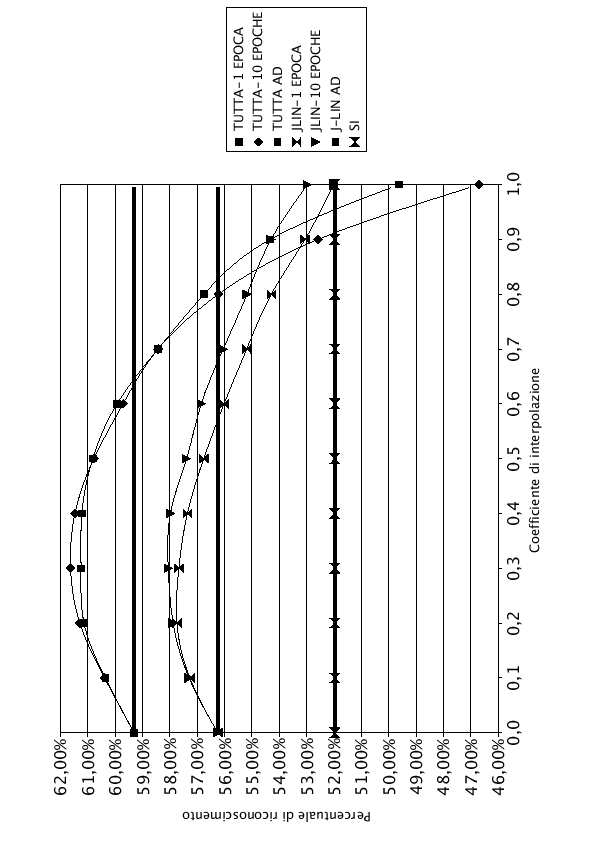
Ottenuti i risultati per ognuno dei 168 parlatori di test, se ne è fatta la media, riportandola in tabella (7.8) e nel grafico (7.10):
|
In tabella (7.8) sono riportati, in grassetto, i valori del coefficiente di interpolazione ![]() per cui si sono ottenuti risultati migliori.
In grafico (7.10), invece, le tre rette orizzontali rappresentano rispettivamente la percentuale di riconoscimento della rete SI, di tutta la rete adattata all'ambiente e di una J-LIN adattata all'ambiente.
per cui si sono ottenuti risultati migliori.
In grafico (7.10), invece, le tre rette orizzontali rappresentano rispettivamente la percentuale di riconoscimento della rete SI, di tutta la rete adattata all'ambiente e di una J-LIN adattata all'ambiente.
Bisogna subito notare che i valori dei coefficienti di interpolazione ottimi, riportati in tabella (7.8) in grassetto, non sono valori assoluti, ma mediati tra i vari parlatori.
Analizzando i risultati si vede come l'interpolazione di tutta la rete e di J-LIN offrano i risultati migliori, rispetto alle reti adattate e alla rete SI. Nel caso dell'interpolazione di tutta la rete, l'aumento è più consistente (2.32%) rispetto all'interpolazione di J-LIN (1.81%). Questa minor efficienza di J-LIN è da attribuire alla maggior diversità dei valori ottimi dei coefficienti di interpolazione ![]() tra i 168 parlatori di test.
tra i 168 parlatori di test.
Come livello assoluto di percentuale di riconoscimento, l'interpolazione di tutta la rete è migliore rispetto all'interpolazione di J-LIN. Questa riduzione della qualità di J-LIN è dovuta dalla minor qualità della rete adattata all'ambiente. Infatti tra l'adattamento di tutta la rete e l'adattamento del solo livello J-LIN esiste una differenza del 3.06%. Questo comportamento non è presente nell'italiano perchè le due reti adattate all'ambiente non offrono una buona percentuale di riconoscimento, perchè addestrate solo con il materiale provveniente da tre parlatori.
Analizzando il ![]() ottimo per ognuno dei 168 parlatori, si nota come esso non sia una costante, ma vari notevolmente da parlatore a parlatore.
Da uno studio della distribuzione dei
ottimo per ognuno dei 168 parlatori, si nota come esso non sia una costante, ma vari notevolmente da parlatore a parlatore.
Da uno studio della distribuzione dei ![]() ottimi si sono ricavati i risultati di tabella (7.9).
ottimi si sono ricavati i risultati di tabella (7.9).
|
Nella tecnica J-LIN, i coefficienti di interpolazione sono distribuiti con maggior regolarità. Prendendo un coefficiente di interpolazione medio, esso porterà un guadagno minore rispetto al interpolazione di tutta la rete, in cui la distribuzione è maggiormente concentrata su alcuni valori di ![]() .
Anche nell'interpolazione di tutta, la rete la perdita di prestazioni nel prendere un coefficiente di interpolazione medio è molto elevata.
.
Anche nell'interpolazione di tutta, la rete la perdita di prestazioni nel prendere un coefficiente di interpolazione medio è molto elevata.
Per quantizzarla si è deciso di andare a ricavare per ogni parlatore la percentuale di riconoscimento corrispondente al ![]() ottimo e di farne la media con quella ricavata per gli altri parlatori.
Si è così ottenuta una percentuale di riconoscimento teorica, che corrisponde al massimo risultato ottinibile, conoscendo il valore ottimo della costante di interpolazione
ottimo e di farne la media con quella ricavata per gli altri parlatori.
Si è così ottenuta una percentuale di riconoscimento teorica, che corrisponde al massimo risultato ottinibile, conoscendo il valore ottimo della costante di interpolazione ![]() .
.
|
Dai risultati visibili in tabella (7.10) si nota come i miglioramenti ottenibili dall'interpolazione di J-LIN sono maggiori, questo perchè la distribuzione dei coefficienti di interpolazione di J-LIN è meno concentrata su alcuni ![]() rispetto alla distribuzione dei coefficienti di interpolazione di tutta la rete.
La percentuale teorica assoluta di riconoscimento rimane maggiore per l'interpolazione di tutta la rete, mentre quella relativa, ottenuta facendo la differenza tra la percentuale di riconoscimento teorica e la percentuale di riconoscimento delle reti adattate all'ambiente, è paragonabile per le due tecniche, in modo coerente con i risultati ottenuti con il database italiano.
rispetto alla distribuzione dei coefficienti di interpolazione di tutta la rete.
La percentuale teorica assoluta di riconoscimento rimane maggiore per l'interpolazione di tutta la rete, mentre quella relativa, ottenuta facendo la differenza tra la percentuale di riconoscimento teorica e la percentuale di riconoscimento delle reti adattate all'ambiente, è paragonabile per le due tecniche, in modo coerente con i risultati ottenuti con il database italiano.
Riuscendo a stimare il valore di ![]() in base al parlatore, si potrebbero ottenere ancora sensibili miglioramenti. Purtroppo per fare studi in questo campo servirebbe un database con molti parlatori e molte frasi per parlatore, non in nostro possesso.
in base al parlatore, si potrebbero ottenere ancora sensibili miglioramenti. Purtroppo per fare studi in questo campo servirebbe un database con molti parlatori e molte frasi per parlatore, non in nostro possesso.
Stefano Scanzio 2007-10-16