Next: 9. Conclusioni Up: 8. Altre tecniche Previous: 8.2.1 Esperimento di validazione Index
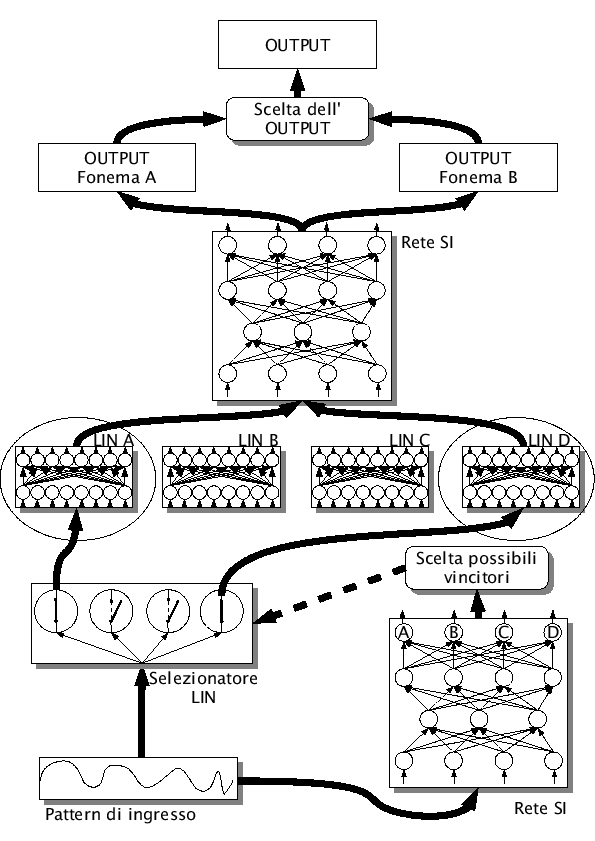
Quando una rete neurale sbaglia il riconoscimento di un pattern proveniente da un determinato parlatore, molto presumibilmente, riconoscerà un fonema particolarmente confondibile con quello giusto. Andando ad analizzare i valori di uscita dei nodi dell'ultimo strato della rete, si vede che tra i valori maggiori, è praticamente sempre presente il nodo vincente, cioè quello riferito al target. La rete sbaglia a riconoscere, ma quando sbaglia lascia sempre un'indicazione sul possibile valore giusto. A seguito di un pattern dato in ingresso, si possono perciò ottenere i nodi di uscita che, con ottima probabilità, conterranno il risultato giusto.
Facendo degli esperimenti si è visto che, prendendo tutti i valori di uscita della rete che stanno al di sopra del 10% del massimo valore, si riesce sempre ad avere, nell'insieme di questi valori, il nodo di uscita giusto.
Indicando con ![]() il massimo valore tra le uscite della rete, si ottiene che la soglia, al di sopra della quale vengono prese le possibili uscite vincitrici, vale:
il massimo valore tra le uscite della rete, si ottiene che la soglia, al di sopra della quale vengono prese le possibili uscite vincitrici, vale:
Nella teoria dei modelli markoviani per il riconoscimento vocale (HMM) si usano modelli separati per ogni fonema, a differenza delle reti neurali in cui tutti i fonemi competono uno contro l'altro. Quello che si è cercato di fare è studiare una tecnica simile a quella utilizzata per gli HMM, da applicare alle reti neurali, al fine ottenere quale, tra l'insieme dei candidati, sia quello esatto.
Le LIN fonetiche nascono proprio per risolvere questo problema. Una volta trovati i possibili fonemi vincitoti, si è pensato di anteporre alla rete delle LIN, con il compito di alzare il valore del fonema esatto e di abbassare gli altri. L'idea consiste, una volta utilizzata la rete per ricavare i possibili vincitori, di eseguire un run-forward per ognuno dei fonemi candidati ad essere vincitori. Anzichè utilizzare la rete generica si utilizza la rete con anteposta una LIN diversa per ogni fonema. Per ottenere una LIN fonetica si è deciso di addestrare una LIN solo con i pattern associati ai fonemi relativi alla LIN. Una LIN addestrata in questo modo dovrebbe favorire in maniere evidente i fonemi per cui è stata addestrata e, almeno secondo le nostre ipotesi, abbassare il valore di uscita della rete quando il pattern non rappresenta il fonema addestrato nella LIN.
Un problema da risolvere è la presenza delle unità transizionali. Per semplicità è stata utilizzata la rete italiana, in cui le unità transizionali non sono raggruppate in classi. Analizzandola, essa presenta nel suo livello di uscita 683 unità, di cui solo i primi 27 sono fonemi, mentre le rimanenti 656 sono unità transizionali. Addestrare 683 LIN, una per ogni nodo di uscita, avrebbe un'occupazione di memoria troppo elevata, per permetterne un utilizzo nelle applicazioni reali. Come approssimazione si è deciso di utilizzare anche i patterns riferiti alle unità transizionali, per addestrare 27 LIN, una per ogni fonema.
Riprendendo la modellazione ad automi sinistra-destra con unità transizionali, la parola ``ciao'' è modellata come: c c-i i i-a a a-o o
Ogni unità transizionale viene modellata con 2 stati. Ad esempio nel caso di c-i, i patterns riferiti al primo stato sono associati alla LIN fonetica di c, mentre i patterns riferiti al secondo sono associati alla LIN fonetica di i.
Facendo qualche modifica di codice al programma di addestramento si sono ottenute, con la procedura appena descritta, 27 LIN fonetiche.
Per il riconoscimento si è utilizzata la seguente procedura ad ogni pattern
Resta ancora da chiarire quale sia la strategia più adatta da utilizzare nel punto 5) al fine di trovare il fonema vincente. Nella nostra implementazioni abbiamo testato due strategie: rotazione migliore per fonema e massima probabilità per nodo.
La strategia ``rotazione migliore per fonema'', mira a correggere i valori del vettore di 683 uscite ottenuto dal run-forward della rete normale (punto 2), con i valori di quei fonemi per cui è stato eseguito il run-forward con la LIN fonetica. Si andranno perciò a sostituire tutti i valori delle unità di output relativi ai fonemi candidati ad essere possibili vincitori e relativi a tutte le unità transizionale ad essi associate. In questo modo restano invariati i valori dei fonemi non candidati ad essere vincenti e si vanno a modificare i valori degli altri, con le relative correzioni apportate dalle LIN fonetiche. Nel caso il fonema vincente attraverso il run-forward della rete neurale tradizionale non sia quello esatto, esso sarà abbassato, mentre quello esatto sarà alzato. Se questi spostamenti saranno sufficienti a far prevalere il valore del fonema corretto rispetto a quello errato, è stato corretto un errore con il conseguente aumento delle prestazioni.
La strategia di scelta del fonema vincente sopra descritta, presenta il problema che la somma delle probabilità delle unità di output non è unitaria. Nelle reti neurali per il riconosciemento vocale si utilizza, nell'ultimo strato della rete, una funzione di tipo softmax che serve a garantire la somma unitaria delle unità di output. Essa serve a facilitare il compito del riconoscitore facendo migliorare la capacità discriminante della rete. Nella seconda strategia, massima probabilità per nodo, si è scelto tra i vettori di output quello con il valore di probabilità maggiore e lo si è utilizzato direttamente come output della rete.
Questa strategia dovrebbe portare ad un miglioramento della qualità di riconoscimento del riconoscitore, a prescindere dal parlatore. Essa può comunque venir proficuamente utilizzata per l'adattamento al parlatore. In tal senso basta adattare 27 LIN fonetiche per ogni parlatore, le quali vanno a bilanciare quei fonemi in cui il parlatore sbaglia maggiormente. Siccome l'occupazione di memoria è 27 volte maggiore rispetto all'utilizzo di una LIN singola, un metodo efficace potrebbe essere quello di addestrare delle LIN fonetiche solo per quei fonemi dove la rete maggiormente sbaglia.
Il tempo di esecuzione di questa tecnica è leggermente maggiore rispetto alle strategia classica LIN. Questo è dovuto al fatto che bisogna fare un run-forward per ogni fonema candidato ad essere vincente. Nonostante ciò è ancora possibile l'esecuzione della strategia in modo real-time, infatti vengono utilizzate molte LIN fonetiche solo quando la rete normale non riesce ad ottenere un nodo di uscita con un valore di probabilità molto più elevato rispetto agli altri.
Sfortunatamente con questa tecnica siamo riusciti ad ottenere risultati paragonabili all'utilizzo della rete normale. In pratica, tutte le volte che compie un errore di riconoscimento, le LIN fonetiche non sono in grado di riuscire a far prevalere il fonema giusto. Addestrando LIN fonetiche si perde il comportamento discriminitavo della rete neurale. Avendo come materiale di addestramento solo patterns riferiti ad un determinato fonema, le LIN fonetiche tendono ad alzare sempre il valore del target per cui sono state addestrate, a prescindere dal pattern che viene dato loro in ingresso. Tra le varie LIN che competono nel trovare il fonema vincente, vince sempre quella che, in concordanza con i pesi fissi della rete SI, riesce ad alzare maggiormente il fonema a lei riferito.
Per cercare di ottenere un comportamento discriminante dalle LIN fonetiche si è provato ad addestrare la LIN anche con dei fonemi diversi.
Ad esempio la LIN riferita al fonema ``a'' è stata così addestrata:
Purtroppo anche questa strategia non ha dato risultati migliori. Una possibile soluzione è quella di fare delle LIN discriminanti tra due fonemi. In pratica, a seguito di un analisi dei fonemi per cui la rete sbaglia maggiormente, è prevedibile che il fonema erroneamente fornito come giusto sia sempre lo stesso. Se questa ipotesi fosse confermata, si potrebbero pensare delle LIN, con la funzione di discriminare solo tra due fonemi. In questo caso si riuscirebbe ad addestrarle senza perderne il comportamento discriminativo. Analizzando le LIN standard da questo punto di vista, esse avrebbero solamente la funzione di riadattare la capacità discriminante della rete, in questo caso tra tutti i fonemi, per i vari parlatori.
Stefano Scanzio 2007-10-16