-
- 1
- Bourland H. e Morgan N.: Connectionist speech recognition: a hybrid approach, Academic Publishers, 1993
- 2
- Burnett D. C.: Rapid speaker adaptation for neural network speech recognizers, 1997
- 3
- PKLab: Introduzione alla neuro computazione, http://www.pklab.net, 1994
- 4
- Furui S.: A training procedure for isolated word recognition sistems, in IEEE Transactions and Acoustics, Speech, and Signal Processing, 1980, pag. 129-136
- 5
- Bellegarda J. R., De Souza P. V., Nádas A. J., Nahamoo D., Picheny M. A. e Bahl L. R.: Robust speaker adaptation using a picewise linear acoustic mapping, in Proceedings of the 1992 IEEE International Conference on Acoustics, Speech, and Signal Processing, San Francisco, 1992, vol. 1, pag. 445-448
- 6
- Matsukoto H. e Inoue H.: A piecewise linear spectral mapping for supervised speaker adaptation, in Proceedings of the 1992 IEEE International Conference on Acoustics, Speech, and Signal Processing, San Francisco, 1992, vol. 1, pag. 449-452
- 7
- Fukuzawa K., Komori Y., Sawai H., Sugiyama M.: A segment-based speaker adaptation neural network applied to continuous speech recognition, in Proceedings of the 1992 IEEE International Conference on Acoustics, Speech, and Signal Processing, San Francisco, 1992, vol. 1, pag. 433-436
- 8
- Huang X.: Speaker normalization for speech recognition, in Proceedings of the 1992 IEEE International Conference on Acoustics, Speech, and Signal Processing, San Francisco, 1992, vol. 1, pag. 465-468
- 9
- Kobayashi T., Uchiyama Y., Osada J. e Shirai K.: Speaker adaptive phoneme recognition based on feature mapping from spectral domain to probabilistic domain, in Proceedings of the 1992 IEEE International Conference on Acoustics, Speech, and Signal Processing, San Francisco, 1992, vol. 1, pag. 457-460
- 10
- Abrash V., Franco H., Cohen M. Morgan N. e Konig Y.: Connectionist gender adaptation in a hybrid neural network / hidden Markov model speech recognition system, in Proceedings of the 1992 International Conference on Spoken Language Processing, Alberta, Canada, 1992, vol. 2, pag 911-914
- 11
- Kosaka T. e Sagayama S.: Tree-structured speaker clustering for fast speaker adaptation, in Proceedings of the 1994 IEEE International Conference on Acoustics, Speech, and Signal Processing, Adelaide, Australia, 1994, vol. 1, pag. 245-248
- 12
- Konig Y. e Morgan N.: Supervised and unsupervised clustering of the speaker space for connectionist speech recognition, in Proceedings of the 1993 IEEE International Conference on Acoustics, Speech, and Signal Processing, Minneapolis, Minnesota, 1993, vol. 1, pag. 545-548
- 13
- Witbrock M. e Haffner P.: Rapid connectionist speaker adaptation, in Proceedings of the 1992 IEEE International Conference on Acoustics, Speech, and Signal Processing, San Francisco, 1992, vol. 1, pag. 453-456
- 14
- Lee C. H., Lin C. H. e Juang B. H.: A study on speaker adaptation of the parameters of continuous density hidden Markov models, in IEEE Transactions on Signal Processing, 1991, pag. 806-814
- 15
- Ohkura K., Sugiyama M. e Sagayama S.: Speaker adaptation based on transfer vector field smoothing with continuous mixture dendity HMMs, in Proceedings of the 1992 International Conference on Spoken Language Processing, Alberta, Canada, 1992, vol. 1, pag. 369-372
- 16
- Hampshire II J. B. e Waibel A. H.: The Meta-Pi network: Builging distributed knowledge representations for robust pattern recognition in IEEE Transaction on pattern analysis and machine intelligence, vol. 4, num. 7, 1992
- 17
- Hampshire II J. B. e Waibel A. H.: The Meta-Pi network: Connectionist rapid adaptation for high-performance multi-speaker phoneme recognition, in Proceedings of the 1990 International Conference on Acoustics, Speech, and Signal Processing, Albuquerque, New Mexico, 1990, pag. 165-169
- 18
- Chen L.: A global optimization algorithm for neural network training, in Proceedings of the 1993 International Joint Conference on Neural Networks, Nagoya, Japan, 1993, vol.1, pag. 443-446
- 19
- Robins A.: Catastrophic forgetting, rehearsal and pseudorehearsal, in Connection Science 7, 1995, pag.123-146
- 20
- Pedreira C. E. e Rohel N. M.: On adaptively trained networks, in Proceeding of the 1993 International Joint Conference on Neural Networks, Nagoya, Japan, 1993, vol. 1, pag. 565-568
- 21
- Fissore L., Ravera F. e Laface P.: Acoustic-phonetic modelling for flexible vocabulary speech recognition, in EUROSPEECH '95,
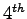 European Conference on Speech Comunication and Technology, Madrid, 1995, pag. 799-802
European Conference on Speech Comunication and Technology, Madrid, 1995, pag. 799-802
Stefano Scanzio
2007-10-16