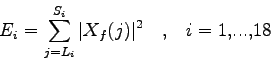Lo scopo del riconoscimento vocale è, dato un segnale in ingresso, riuscire a ricavare, nel modo più corretto possibile ciò che è stato detto. A tale scopo i segnali in ingresso, vengono trattati con delle tecniche opportune e riconosciuti tramite algoritmi che si basano su principi diversi.
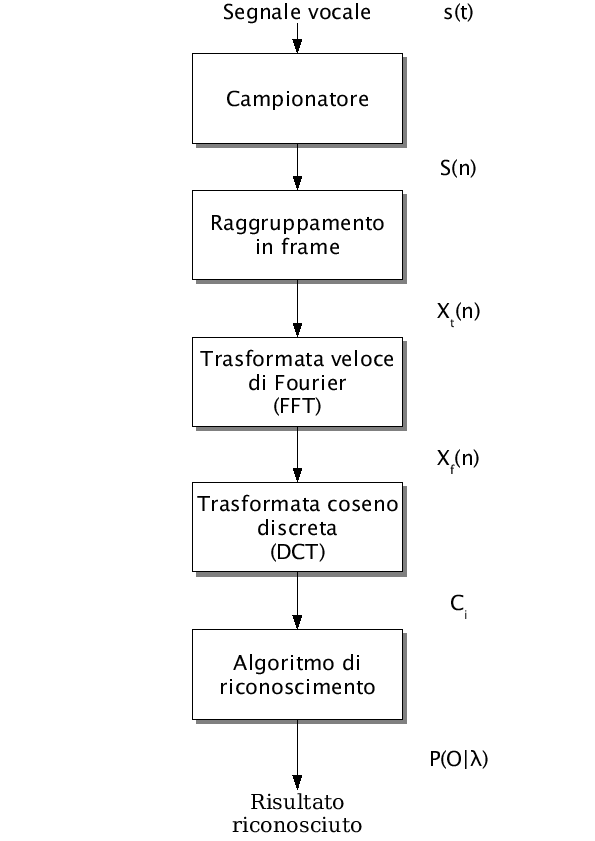
In figura 2.7 si possono notare i vari blocchi che compongono un riconoscitore vocale.
Lo schema è stato volutamente semplificato allo scopo di dare una veloce introduzione all'argomento.
In ingresso si ha un segnale vocale.
Essa viene rielaborata al fine di costituire un vettore di ingresso all'algoritmo di riconoscimento, costituito:
- dai parametri o coefficienti cepstrali (
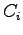 )
)
- dall'energia totale (
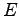 )
)
- dalle variazioni e dalle variazioni delle variazioni dei parametri (
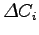 ,
,
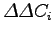 ,
, 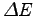 ,
,
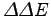 )
)
Questi parametri saranno ottenuti a seguito di una serie di trasformazioni che mireranno ad ottenere solo quelle caratteristiche vocali utili al riconoscimento.
Figure 2.7:
Schema a blocchi: riconoscimento a partire dal segnale vocale
|
|
In primo luogo viene compiuto un passaggio dal dominio continuo a quello discreto campionando il segnale vocale 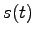 e ottenendo
e ottenendo 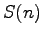 . Nel nostro riconoscitore si è utilizzata una campionatura a 8 KHz e una precisione di 8 bit.
Il segnale ottenuto viene poi raggruppato in frames.
Le caratteristiche dell'apparato vocale umano non variano rapiamente nel tempo e possono essere considerate invarianti per brevi intervalli detti frame.
Il segnale vocale umano può essere quindi considerato semi-stazionario, ovvero stazionario per periodi relativamente brevi, nel nostro caso di 20 ms.
Un frame viene ottenuto spostando una finestra rettangolare ampia
. Nel nostro riconoscitore si è utilizzata una campionatura a 8 KHz e una precisione di 8 bit.
Il segnale ottenuto viene poi raggruppato in frames.
Le caratteristiche dell'apparato vocale umano non variano rapiamente nel tempo e possono essere considerate invarianti per brevi intervalli detti frame.
Il segnale vocale umano può essere quindi considerato semi-stazionario, ovvero stazionario per periodi relativamente brevi, nel nostro caso di 20 ms.
Un frame viene ottenuto spostando una finestra rettangolare ampia 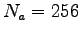 campioni, di
campioni, di 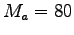 campioni lungo tutta la durata
campioni lungo tutta la durata 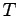 del segnale. Si ha dunque:
del segnale. Si ha dunque:
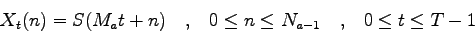 |
(2.20) |
Da (2.20) si può notare che gli 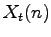 sono sovrapposti, hanno durata di 20 ms e iniziano ogni 10 ms.
Dal segnale si passa nel domino delle frequenze per mezzo della trasformata veloce di Fourier (FFT) ottenendo
sono sovrapposti, hanno durata di 20 ms e iniziano ogni 10 ms.
Dal segnale si passa nel domino delle frequenze per mezzo della trasformata veloce di Fourier (FFT) ottenendo 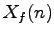 .
Il segnale ottenuto viene fatto passare in un banco di 18 filtri passa banda, progettati in base ad un modello che rispecchia le caratteristiche del sistema uditivo umano.
Per ogni frame viene calcolata l'energia del segnale relativa all'i-esimo filtro:
.
Il segnale ottenuto viene fatto passare in un banco di 18 filtri passa banda, progettati in base ad un modello che rispecchia le caratteristiche del sistema uditivo umano.
Per ogni frame viene calcolata l'energia del segnale relativa all'i-esimo filtro:
dove 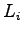 e
e 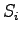 sono gli estremi in frequenza della banda relativa al filtro i-esimo e
sono gli estremi in frequenza della banda relativa al filtro i-esimo e 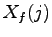 è il j-esimo campione ricavato dalla trasformata veloce di Fourier.
Applicando una trasformata coseno discreta (DCT) al fine di decorrelare le bande, si ottengono 17 parametri cepstrali di cui solo i primi 12 vengono usati dal riconoscitore:
è il j-esimo campione ricavato dalla trasformata veloce di Fourier.
Applicando una trasformata coseno discreta (DCT) al fine di decorrelare le bande, si ottengono 17 parametri cepstrali di cui solo i primi 12 vengono usati dal riconoscitore:
![\begin{displaymath}
C_i=\sum_{j={1}}^{18} log(E_j) cos\left[ i\left( j-\frac{1}{2}\right) \frac{\pi}{18}\right] \quad , \quad i=1,...,17
\end{displaymath}](img91.png) |
(2.21) |
Viene anche calcolata l'energia totale:
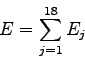 |
(2.22) |
All'ingresso dell'algoritmo di riconoscimento vengono anche passate le variazioni dei parametri cepstrali (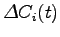 ) e le variazioni delle variazioni (
) e le variazioni delle variazioni (
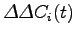 ), chiamati parametri cepstrali differenziali. Essi vengono calcolati per approssimazione delle derivate temporali dei coefficienti cepstrali, su una finestra pari a
), chiamati parametri cepstrali differenziali. Essi vengono calcolati per approssimazione delle derivate temporali dei coefficienti cepstrali, su una finestra pari a 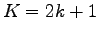 frame. Nel caso del nostro riconoscitore
frame. Nel caso del nostro riconoscitore 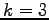 . Si ottiene:
. Si ottiene:
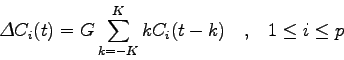 |
(2.23) |
dove:
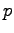 è il numero di parametri cepstrali per ogni frame
è il numero di parametri cepstrali per ogni frame
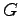 è una costante
è una costante
Si calcolano poi la derivata e la derivata doppia di e si applica la (2.23) sui ottenuti in precedenza.
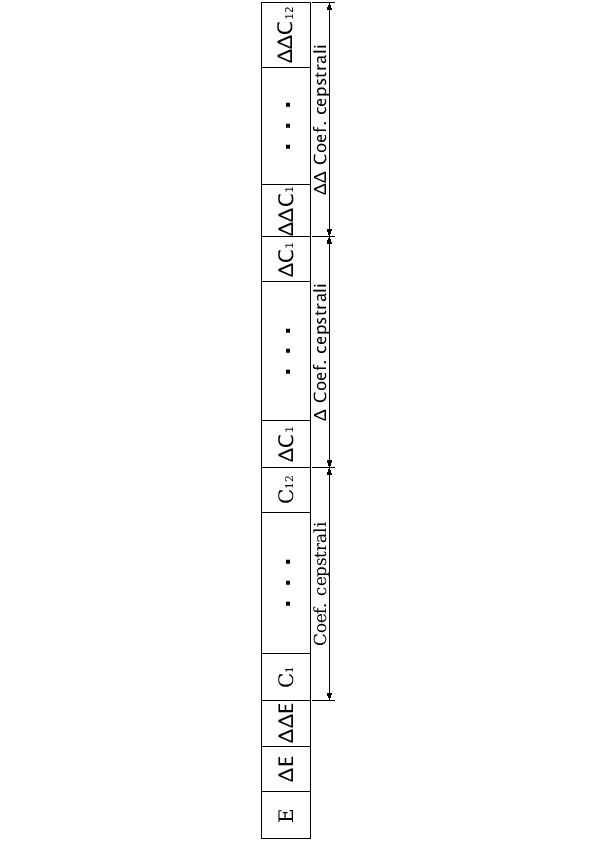
Ogni frame in ingresso al riconoscitore sarà perciò rappresentato da:
- , ,
- 12 coefficienti cepstrali ()
- 24 coefficienti cepstrali differenziali: 12 () e 12 (
)
ottenendo un totale di 39 parametri per frame (Figura 2.8).
Figure 2.8:
Composizione di un frame
|
|
Una volta elaborato il segnale, verrà passato all'algoritmo che svolgerà il riconoscimento.
Come è stato visto in precedenza per quanto riguarda la tecnologia neurale, per il riconoscimento, sia che si utilizzi una rete, sia che si usino altre tecniche, bisogna sempre compiere una fase di training con il compito di addestrare il modello.
Esistono due tecniche utilizzate per stimare i modelli utili al riconoscimento vocale:
- Hidden Markov Model (HMM)
- Modelli ibridi markoviani/neurali (HMM-NN)
Stefano Scanzio
2007-10-16