La rete neurale utilizzata è stata progettata LOQUENDO S.p.A.. Essa rispecchia la struttura base descritta nel capitolo precedente, con alcune modifiche e miglioramenti.
Verrà descritta in dettaglio la rete inglese: la rete italiana differisce solo per il fatto di avere 683 unità di output anzichè 949.
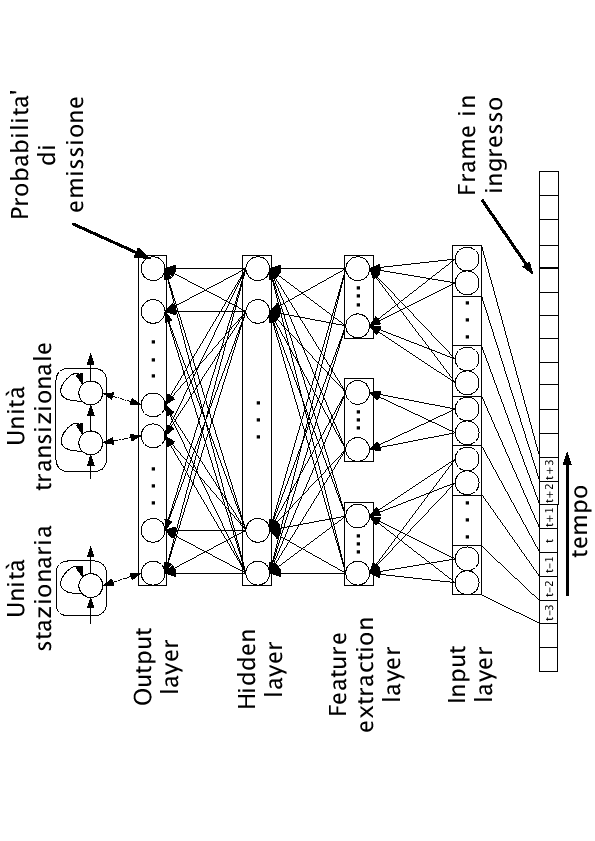
Una schematizzazione macroscopica della rete neurale è descritta in figura (4.1).
Figure 4.1:
Rappresentazione schematica della rete neurale utilizzata
|
|
La finestra di input è ampia 7 frames, ognuno dei quali contiene 39 parametri (energia, 12 coefficienti cepstrali, le loro derivate prime e le loro derivare seconde). I primi e gli ultimi 3 frames rappresentano i frames di contesto, mentre il quarto frame viene chiamato frame centrale.
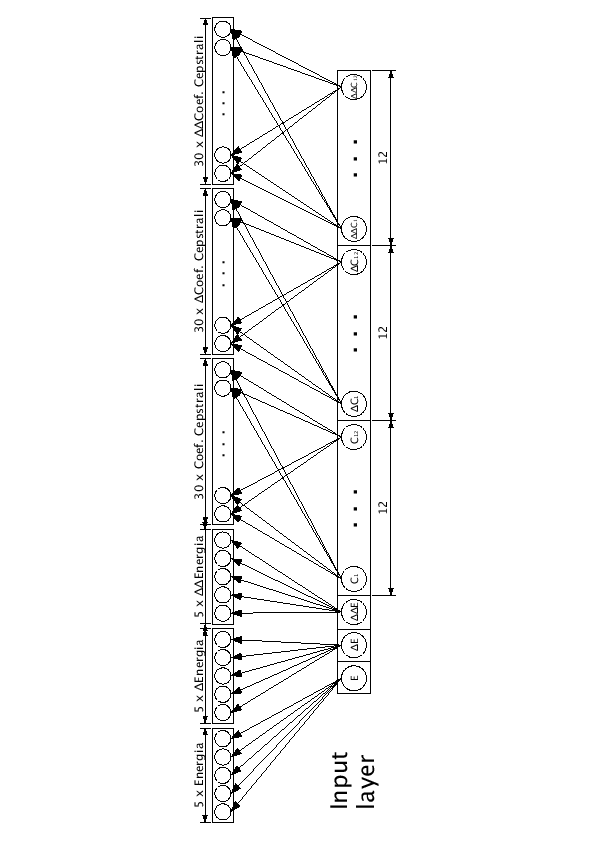
Dopo lo stadio di input (input layer) composto da 273 unità, il primo livello intermedio (feature extraction layer) è diviso in tre blocchi di contesto, il primo per il contesto sinistro, il secondo per quello centrale, l'ultimo per il contesto destro. Ogni blocco compie una funzione di estrazione delle caratteristiche (feature extraction). In pratica vengono tenuti separati i valori di energia, dei 12 coefficienti cepstrali, delle loro derivate prime e delle loro derivare seconde (figura 4.2).
Figure 4.2:
Rappresentazione schematica dell'estrazione delle caratteristiche nel features extraction layer per il contesto centrale
|
|
I valori associati alle energie e alle loro variazioni vengono collegati a 5 unità del livello superiore, mentre quelli riferiti ai coefficienti cepstrali sono completamente interconnessi a 30 unità. Il feature extraction layer è perciò composto da 315 unità, 105 per i 3 frame di contesto sinistro, 105 per il frame centrale e 105 per i 3 frame di contesto destro. È stato valutato empiricamente che questa conoscenza a priori indotta nella struttura della rete, porta a prestazioni migliori rispetto ad un livello interamente interconnesso. L'hidden layer è invece composto da 300 unità ed è competamente interconnesso con le unità sottostanti. Tutti questi livelli usano la funzione sigmoide per generare l'output delle singole unità.
Per quanto riguarda l'output layer è composto da 949 unità, che rappresentano la somma del numero di fonemi e delle unità transizionali di cui più avanti nel capitolo verrà spiegato il significato. Anche questo livello è completamente interconnesso al livello inferiore. La differenza sostanziale è che in questo livello viene utilizzata una funzione di tipo softmax. Questo livello è l'unico punto di diversità tra la rete italiana e quella inglese, infatti nel caso italiano ci sono 683 unità.
Le probabilità di emissione fornite in uscita dalla rete servono per l'utilizzo del modello ad automi sinistra-destra delle parole, che si può notare nella parte alta della rete di figura (4.1).
Le probabilità di emissione, assieme alle probabilità di transizione da uno stato al successivo, permettono il passaggio da uno stato all'altro.
La rete inglese è quindi formata da 1837 unità, per un totale di 398865 archi e 1837 bias, mentre la rete italiana è composta da 1571 unità, da 319065 archi e 1571 bias (tabella 4.1).
Table 4.1:
Numero di unità, archi e bias presenti nella rete italiana e inglese utilizzate
| Rete |
Unità |
Archi |
Bias |
| Inglese |
1837 |
398865 |
1837 |
| Italiana |
1571 |
319065 |
1571 |
|
Si nota che i file utilizzati per salvare pesi e bias di una rete, sono file di dimensione piuttosto elevata, circa 1.6 MByte.
Stefano Scanzio
2007-10-16