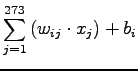5.1.1 Linear Input Network Adaptation (LIN)
La tecnica di adattamento al parlatore LIN è una soluzione già presente nella letteratura del riconoscimento vocale da parecchi anni.
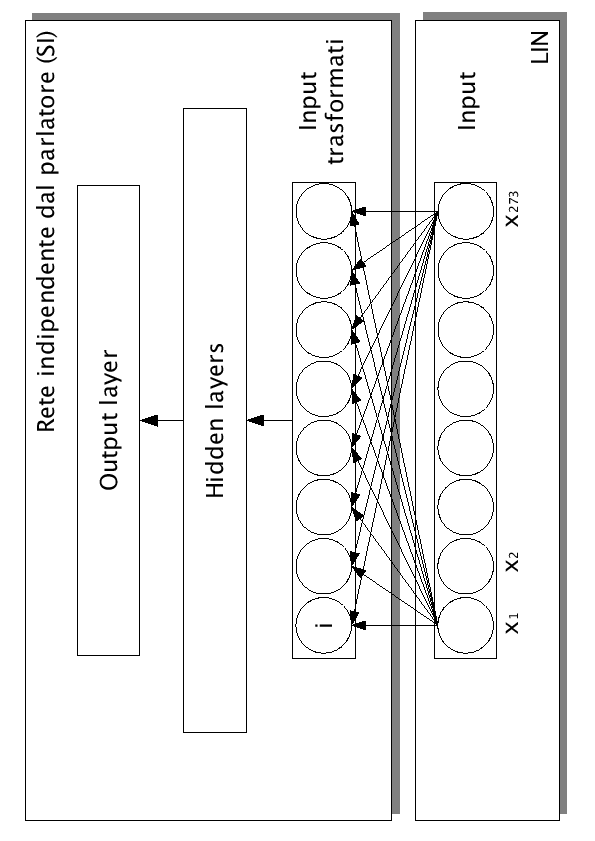
Questa tecnica consiste nell'aggiungere un ulteriore strato alla rete neurale rappresentato da una rete lineare (figura 5.1).
Figure 5.1:
LIN standard collegata ad una rete indipendente al parlatore (SI)
|
|
Esso ha il compito di realizzare una trasformazione lineare dello spazio dei parametri di ingresso. Quando la LIN viene addestrata con dati provvenienti da uno stesso parlatore, essa ha la funzione di compiere uno trasformazione lineare al fine di rendere il più possibile i frame prodotti da un determinato parlatore, simili a quelli di un parlatore standard. Le formule che regolano questa trasformazione, per una generica unità 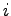 e un generico vettore di ingressi
e un generico vettore di ingressi
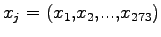 sono:
sono:
Si nota come il valore di ogni unità sia legato in modo lineare al vettore di ingresso, tramite i pesi della LIN 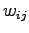 . La funzione (5.2), in questo caso non compie nessuna trasformazione.
Nella sua versione standard è formata da 273 unità completamente interconnesse allo stadio di ingresso della rete indipendente dal parlatore (SI). Essa sarà perciò costituita da 74529 archi e da 273 bias, un numero di pesi decisamente grande per una trasformazione lineare e per poche frasi.
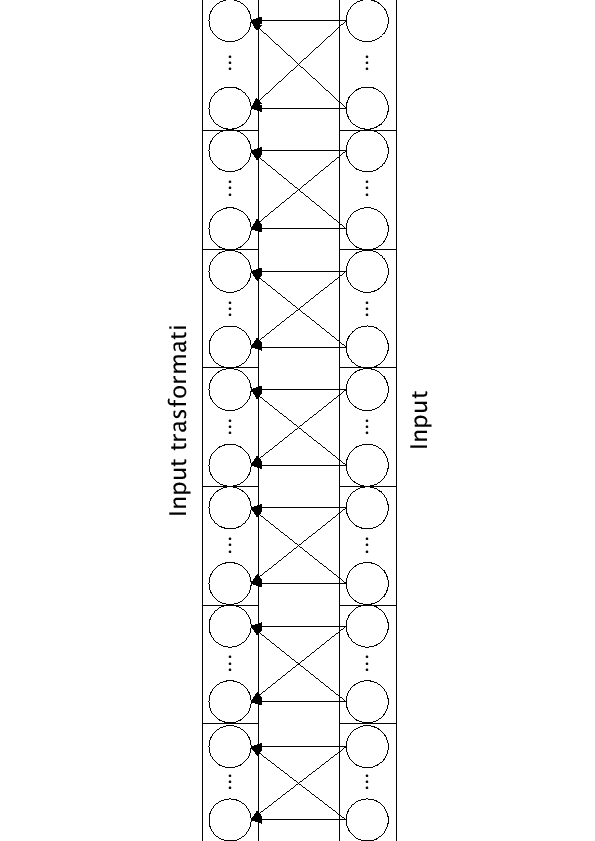
Per avere maggiore robustezza statistica nella stima dei parametri è possibile collegare la LIN con il resto della rete mediante 7 blocchi da 39 unità. Si riescono ad ottenere risultati di poco peggiori rispetto alla LIN standard, ma diminuendo drasticamente il numero di pesi della rete. Le formule (5.1) e (5.2), praticamente non subiscono nessuna modifica, tranne la (5.1) in cui l'indice
. La funzione (5.2), in questo caso non compie nessuna trasformazione.
Nella sua versione standard è formata da 273 unità completamente interconnesse allo stadio di ingresso della rete indipendente dal parlatore (SI). Essa sarà perciò costituita da 74529 archi e da 273 bias, un numero di pesi decisamente grande per una trasformazione lineare e per poche frasi.
Per avere maggiore robustezza statistica nella stima dei parametri è possibile collegare la LIN con il resto della rete mediante 7 blocchi da 39 unità. Si riescono ad ottenere risultati di poco peggiori rispetto alla LIN standard, ma diminuendo drasticamente il numero di pesi della rete. Le formule (5.1) e (5.2), praticamente non subiscono nessuna modifica, tranne la (5.1) in cui l'indice 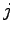 varia a gruppi di 39. In questo modo si riesce ad ottenere una LIN di soli
varia a gruppi di 39. In questo modo si riesce ad ottenere una LIN di soli
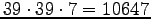 archi e di 273 bias. Nei nostri esperimenti è stata utilizzata quest'ultima struttura (figura 5.2).
archi e di 273 bias. Nei nostri esperimenti è stata utilizzata quest'ultima struttura (figura 5.2).
Figure 5.2:
LIN collegata a blocchi
|
|
Durante il training di una LIN i pesi della rete SI vengono congelati: non si permette cioè all'algoritmo di back-propagation di modificarli. La LIN viene inizializzata alla matrice identità: si mettono cioè a 1 tutti i pesi che collegano direttamente l'unità di input con la relativa unità degli input trasformati, mentre si inizializzano a 0 tutti gli altri archi che agiscono trasversalmente.
Il training porta alla modifica dei pesi della LIN, che si polarizza per riconoscere nel modo migliore le frasi pronunciate da quel determinato parlatore.
Questa tecnica non deve essere vista solo come un mapping spettrale dei parametri in input in senso classico, ma piuttosto come una trasformazione dell'intero sistema indipendente dal parlatore, attraverso l'aggiunta di nuovi parametri e la loro stima. Infatti è vero che la LIN opera un mapping spettrale dei parametri, ma lo opera in modo da massimizzare le prestazioni del sistema complessivo.
Il metodo LIN presenta due vantaggiose caratteristiche:
- non richiede di modificare tutti i parametri del modello neurale, ma è un appendice di dimensioni ridotte che si antepone al modello indipendente dal parlatore e lo adatta ad un parlatore specifico. Quindi può essere conveniente dal punto di vista sistemistico, in quanto per ogni parlatore è necessario memorizzare solo la sua specifica LIN, mentre il modello SI, che è di gran lunga più grande come occupazione di memoria, è comune a tutti i parlatori
- si presta anche al apprendimento unsupervised, in cui, come spiegato nel capitolo 1, si utilizzano direttamente le uscite del riconoscitore, senza intervento umano per la trascrizione, fornendo un adattamento in linea dei modelli, durante l'interazione con il sistema
Stefano Scanzio
2007-10-16