5.2.3 Variando il numero di epoche
Nel precedente esperimento si è osservato che i learning rates ottimali per le varie tecniche di adattamento sono 0.0002 e 0.00002.
Nella successiva prova si è variato il numero di epoche di addestramento, per entrambi i learning rate sopra menzionati, al fine di vedere se ci sono miglioramenti nelle prestazioni generali e se alcune tecniche risentono maggiormente di un aumento del numero di epoche, rispetto ad altre.
Si sono eseguite 2, 3, 5 epoche di addestramento rispettivamente per un learning rate di 0.0002 e di 0.00002. Gli altri parametri di configurazione del programma di addestramento sono quelli di sezione (6.1.3).
In tabella (5.3) sono riportati i risultati per gli esperimenti eseguiti con un learning rate pari a 0.0002, mentre in tabella (5.4) sono riportati quelli riferiti ad un learning rate di 0.00002.
Si nota come un aumentare del numero di epoche di addestramento abbia un effetto positivo su tutte le tecniche e con entrambi i valori di learning rate.
Table 5.3:
Percentuale di riconoscimento al variare del numero di frasi e di epoche di addestramento del parlatore DM con un learning rate di 0.0002
|
|
Table 5.4:
Percentuale di riconoscimento al variare del numero di frasi e di epoche di addestramento del parlatore DM con un learning rate di 0.00002
|
|
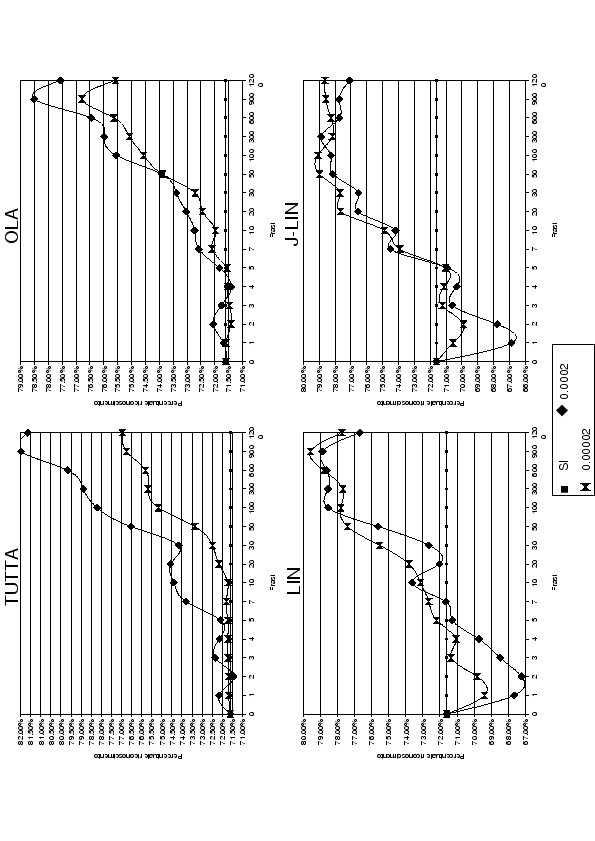
Figure 5.7:
Percentuale di riconoscimento al variare del numero di frasi di addestramento del parlatore DM
|
|
Il alcuni casi, all'aumentare del numero di epoche di training, si nota una diminuzione della qualità di riconoscimento della rete.
Questo effetto può essere presumibilmente provocato da due situazioni:
- quando il numero di frasi di training è piccolo. In questo caso, continuando ad addestrare la rete per diverse volte con le stesse frasi, si provoca una polarizzazione della rete su di esse, peggiorandone notevolmente le prestazioni per quelle frasi di test in cui non è presente nel addestramento una frase simile
- quando è raggiunta la convergenza. Dopo un determinato numero di epoche di addestramento la rete raggiunge una convergenza. Tutti i pesi della rete si trovano ad oscillare attorno ad un minimo locale da cui, con le frasi di training utilizzate, non possono più uscire. Le prestazioni, anche aggiungendo altre epoche di training, non otterranno miglioramenti e oscilleranno, leggermente, attorno ad un valore.
In ogni caso, il tempo di addestramento è linearmente proporzionale al numero di epoche.
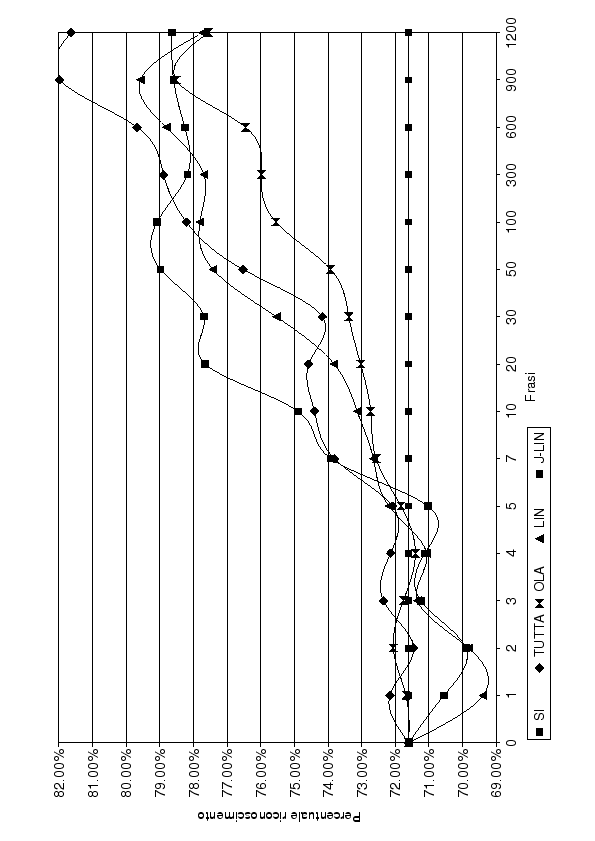
Figure 5.8:
Percentuale di riconoscimento al variare del numero di frasi di addestramento del parlatore DM
|
|
Eccedere con il numero di epoche porta, quindi, ad un aumento sostanziale del tempo di training, senza un corrispettivo aumento delle prestazioni. Dai dati sperimentali si nota come 5 epoche possano ancora dare dei miglioramenti significativi, sebbene il tempo di addestramento sia già elevato. Nell'esperimento, per addestrare la rete con 1200 frasi e 5 epoche, si sono impiegate circa 20 ore utilizzando un microprocessore pentium 3 a 800 MHz.
Nei grafici (5.7) sono stati riportati i risultati delle tabelle (5.3) e (5.4) per i quattro metodi di adattamento addestrati con 5 epoche.
Si nota nettamente che LIN e J-LIN funzionano meglio con un learning rate basso, mentre l'adattamento di tutta la rete e OLA danno risultati migliori con il learning rate di 0.0002.
Questo risultato molto importante è da attribuire, come conferma di quanto discusso in sezione (5.2.2), al fatto che LIN e J-LIN hanno molti meno pesi da addestrare, quindi, un learning rate elevato, porta ad una perdita più rapida delle informazioni acquisite dai pattern precedenti.
Come riepilogo finale in grafico (5.8) sono riportati i risultati migliori, per le varie tecniche, ottenuti per il parlatore DM.
In particolare, l'addestramento di tutta la rete e di OLA con un learning rate di 0.0002 e 5 epoche e l'addestramento di di LIN e J-LIN con un learning rate di 0.00002 e 5 epoche.
In modo coerente con quanto detto finora si può notare come la tecnica J-LIN da 7 a 100 frasi di addestramento offra i risultati migliori. Aggiungendo ulteriori frasi di addestramento non vi è miglioramento e i risultati si attestano sul 78.50%. Per ottenere miglioramenti maggiori non basta più compiere una trasformazione sui dati di ingresso, ma si dovrebbe procedere con l'addestramento dell'intera rete SI. Dopo le 100 frasi, infatti, l'adattamento di tutta la rete supera i risultati di J-LIN attestandosi al 82%. LIN e OLA rimangono praticamente sempre sotto all'adattamento di tutta la rete o di J-LIN.
Durante le prime 5 frasi tutte le tecniche oscillano, in modo meno pronunciato l'addestramento di tutta la rete e OLA , attestandosi in prossimità del valore ottenuto tramite la rete SI.
Stefano Scanzio
2007-10-16