Next: 5.4 Conclusioni Up: 5. Tecniche base di Previous: 5.2.3 Variando il numero Index
Per l'esperimento sono state addestrate LIN, J-LIN, OLA e tutta la rete con 1, 2, 3, 4, 5, 7, 10, 20, 30, 50, 100, 300, 600, 900 e 1200 frasi di training. Per LIN e J-LIN si è utilizzato un learning rate di 0.00002, mentre per OLA e per l'addestramento di tutta la rete si è utilizzato un learning rate di 0.0002.
Gli altri parametri dell'esperimento sono:
|
È interessante osservare come la stessa rete fornisca risultati molto differenti per i vari parlatori. L'adattamento al parlatore nasce proprio dall'esigenza di eliminare questa incapacità della rete di riconoscere in modo adeguato alcuni parlatori, nel nostro caso DM.
In tabella (5.6) sono invece riportati i valori relativi della percentuale di riconoscimento per i quattro parlatori e i quattro modelli, rispetto alla rete SI. I risultati rispecchiano perfettamente quanto descritto nei paragrafi precedenti: il comportamento di J-LIN è vincente nel caso di poche frasi di training, mentre all'aumentare in modo consistente delle frasi è preferibile adattare l'intera rete.
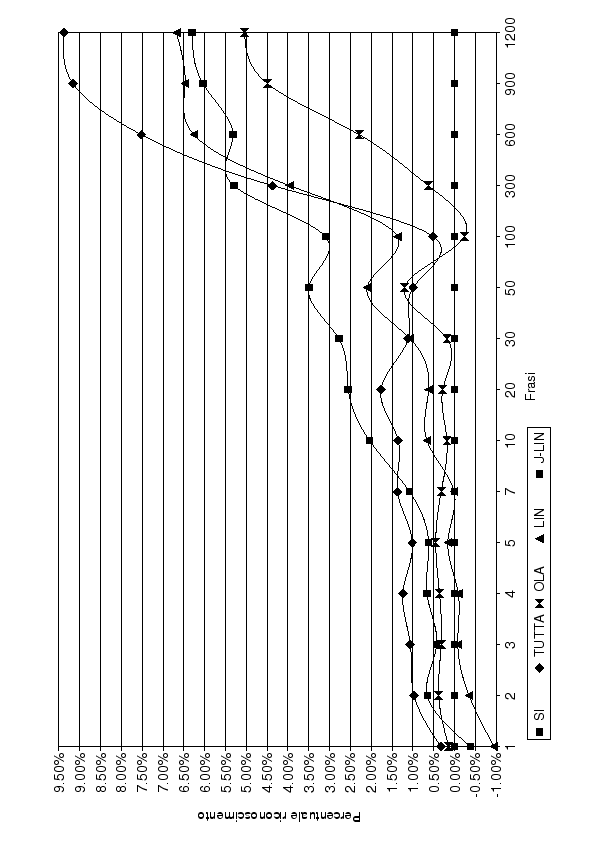
Al fine di ottenere un dato riassuntivo della qualità delle quattro tecniche, si è fatta la media delle tabelle (5.6) ottenendo l'unica tabella (5.7) e il grafico (5.9) che rappresentano, per questo gruppo di parlatori, il comportamento medio delle tecniche analizzate.
|
|
Tutte le tecniche, eccetto LIN, già dopo due frasi di addestramento forniscono un contributo positivo. Tra le 10 e le 300 frasi J-LIN è sicuramente la soluzione ottimale permettendo di ottenere in quell'intervallo un aumento compreso tra il 2% e il 5%. Nell'intervallo tra 1 e 10 frasi di addestramento non vi è prevalenza di nessuna tecnica sull'altra: l'adattamento di tutta la rete sembra funzionare meglio, ma questo comportamento è dovuto alla resistenza della rete nell'imparare nuove frasi, infatti, fino a 100 frasi, oscilla sempre attorno ad un miglioramento del 1%. Oltre le 300 frasi l'adattamento di tutta la rete fornisce risultati consistenti, riuscendo ad apportare un miglioramento superiore al 9%.
Stefano Scanzio 2007-10-16