Next: 6.2.3 Considerazioni Up: 6.2 K-LIN ottimizzata Previous: 6.2.1 Struttura e funzionamento Index
![[*]](crossref.png) . L'unica differenza consiste nell'aver utilizzato una struttura 4-LIN ottimizzata e nell'aver imposto il valore di batchsize pari a 1, come spiegato nella sezione precedente.
In tabella (6.7) e nel grafico (6.10) sono riportati i risultati dell'esperiemento:
. L'unica differenza consiste nell'aver utilizzato una struttura 4-LIN ottimizzata e nell'aver imposto il valore di batchsize pari a 1, come spiegato nella sezione precedente.
In tabella (6.7) e nel grafico (6.10) sono riportati i risultati dell'esperiemento:
|
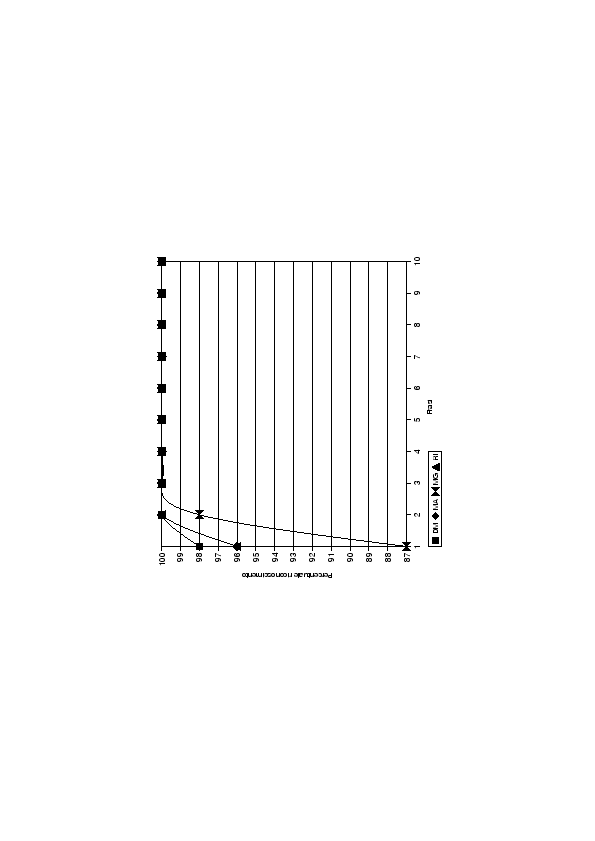
Ad una prima analisi appare evidente come i risultati di questa tecnica siano decisamente migliori. In questo modello, le LIN sono addestrate con 285 frasi per ogni parlatore, un numero sufficiente per avere dei modelli robusti, capaci di garantire una buona qualità di riconoscimento del parlatore. Bastano infatti appena 3 frasi, per individuare, con una precisione del 100%, il parlatore giusto. Nel modello K-LIN con matrice identità, per ottenere gli stessi risultati, ne servivano 9. È da notare che già con 2 frasi si ottengono percentuali sempre superiori al 98%. In questo caso il parlatore più debole, a differenza del modello K-LIN con matrice identità, è MG, che con 1 frase, raggiunge solo una percentuale del 87%.
|
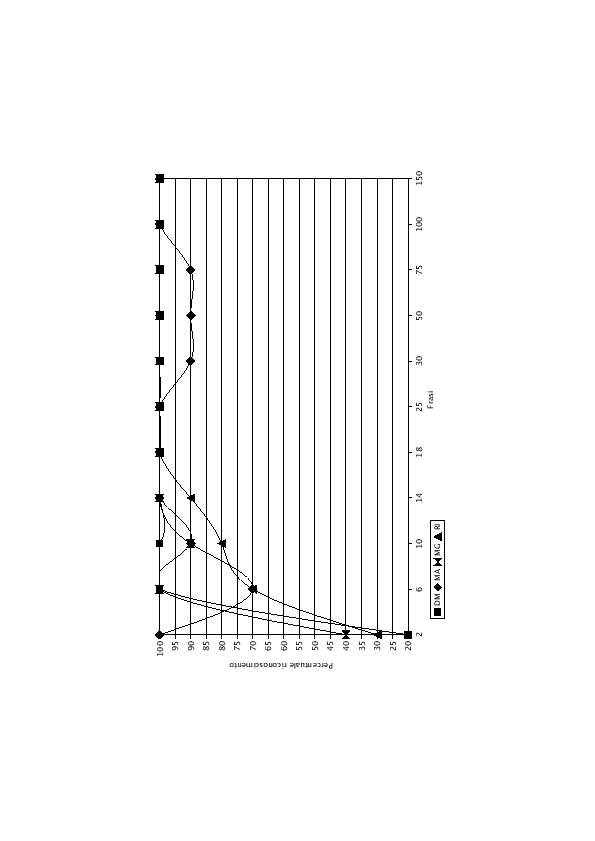
I risultati di tabella (6.8) e del grafico (6.11), sono anche in questo caso molto incoraggianti. Dopo 14 frasi di addestramento delle LIN riferite al parlatore, tutti i parlatori vengono riconosciuti con una percentuale non inferiore al 90%. Confrontato con la tecnica K-LIN standard si nota che, per i quattro parlatori italiani e con 14 frasi di training dei modelli, la percentuale di riconoscimento per il parlatore DM è del 52.5%, un valore decisamente basso, visto anche il numero ridotto di parlatori con cui è stato compiuto l'esperimento. A 16 frasi la percentuale di riconoscimento è del 100% per tutti i parlatori. Nonostante questo dato positivo, si nota dal grafico che le LIN non hanno ancora raggiunto la convergenza. Tra le 30 e le 75 frasi, infatti, la percentuale di riconoscimento del parlatore MA scende al 90%, per poi attestarsi in modo fisso al 100%, dopo 100 frasi di addestramento.
|
Questo comportamento è facilmente spiegabile. Sebbene a 16 frasi si riesca ad ottenere già il 100%, i modelli che rappresentano i parlatori non sono ancora perfettamente addestrati. In pratica i pesi delle LIN vengono ancora modificati dai nuovi patterns che vengono dati in ingresso alla rete. Una frase che contiene parole simili ad una frase pronunciata da un altro parlatore, è ancora in grado di modificare il comportamento del modello, facendone sbagliare il riconoscimento. Aumentando però le frasi di addestramento, le LIN arrivano ad una situazione di convergenza in cui nuove frasi non servono più a dare informazioni nuove sul parlatore. Da questo punto in avanti (100 frasi), i modelli riferiti ad ogni parlatore sono da considerarsi addestrati e ulteriori frasi di addestramento non porteranno miglioramento al modello.
Anche con 4-LIN ottimizzata, si nota come il modello tenda a confondere in maniera maggiore i parlatori dello stesso sesso: DM è confuso con RI e MA è confuso con MG.