Next: 7.2.2 Esperimenti compiuti sul Up: 7.2 Esperimenti effettuati Previous: 7.2 Esperimenti effettuati Index
Nella prima parte di questi esperimenti si è deciso di adattare i modelli SD con 10 epoche. Questo per permettere ai modelli di raggiungere la convergenza che, nel caso dell'algoritmo di back-propagation, avviene per successive approssimazioni. In questo modo è stato analizzato con più precisione il comportamento della tecnica di interpolazione. Fare un addestramento su 10 epoche è un procedimento molto lungo, quindi si sono ripetuti gli esperimenti con una singola epoca di addestramento dei modelli SD. I tempi vengono così ridotti di 10 volte, permettendo di utilizzare questa tecnica in un'applicazione funzionante in tempo reale.
Per gli esperimenti è stato utilizzato il parlatore DM per l'addestramento della rete SD, mentre i parlatori MA, MG, e RI per eseguire l'adattamento al canale. I modelli adattati al canale (AD), sono stati addestrati sempre con 10 epoche e con le 3600 frasi di training appartenenti ai parlatori MA, MG e RI. Si è deciso di utilizzare 10 epoche, poichè l'adattamento al canale è un procedimento che può essere eseguito in modo batch, in fase di preparazione dell'applicazione per il riconoscimento. Non essendoci perciò grossi vincoli temporali, si è pensato di addestrare la rete AD nel modo più accurato possibile.
Sono stati compiuti esperimenti interpolando l'intera rete, delle LIN e delle J-LIN. Nell'addestramento delle tre tecniche sono state utilizzate 1, 2, 3, 4, 5, 7, 10, 30, 50, 100, 300, 600, 900 e 1200 frasi di training del parlatore DM.
|
|
|
|
|
Nell'eseguire quest'esperimento ci siamo posti tre obiettivi.
Verificare quale tra le tre tecniche fornisca risultati migliori. Verificare il comportamento della tecnica di interpolazione dei pesi, con un numero elevato di frasi di addestramento dei modelli SD. Cercare una legge che descriva la variazione del coefficiente di interpolazione ottimo ![]() , al variare del numero di frasi di addestramento.
, al variare del numero di frasi di addestramento.
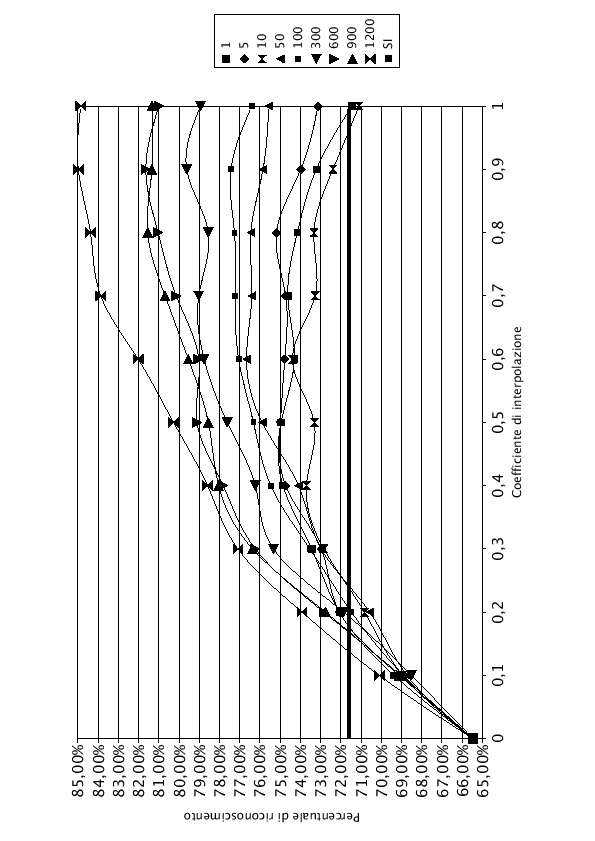
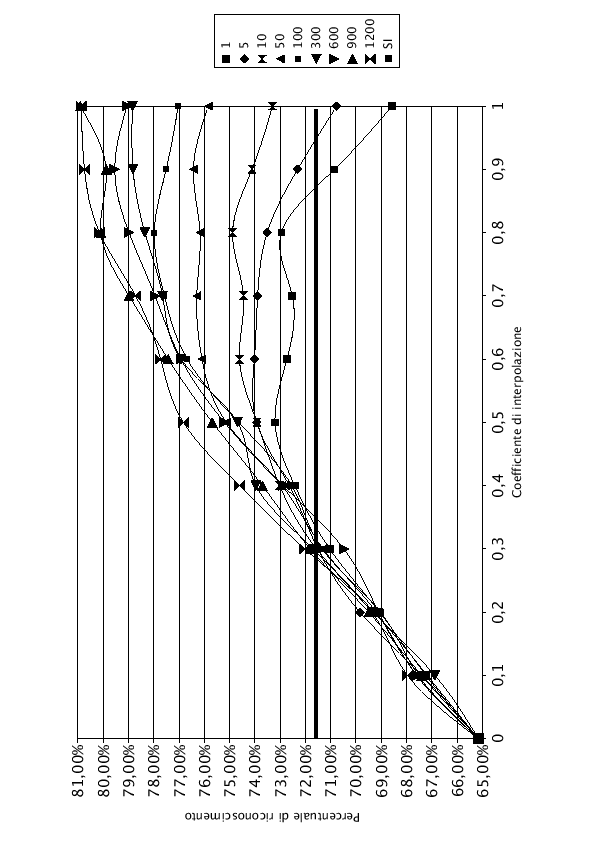
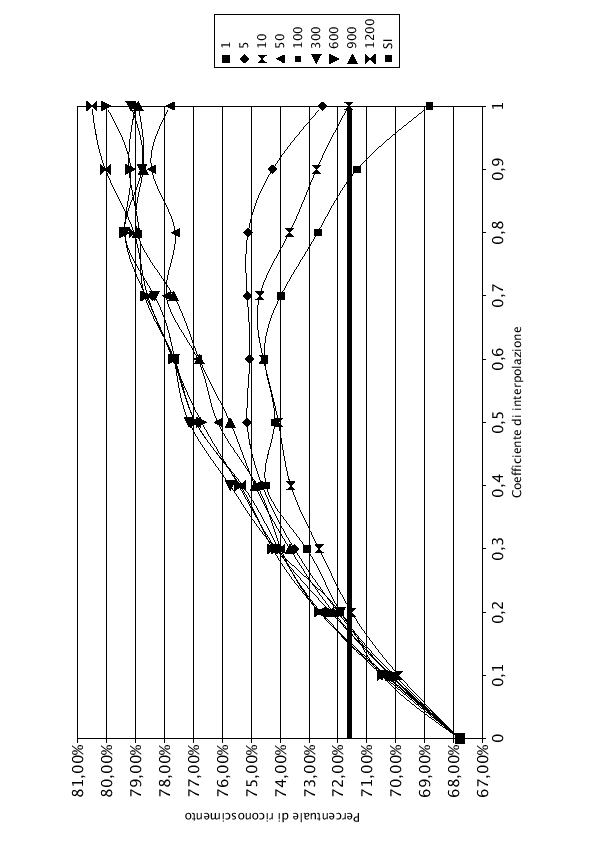
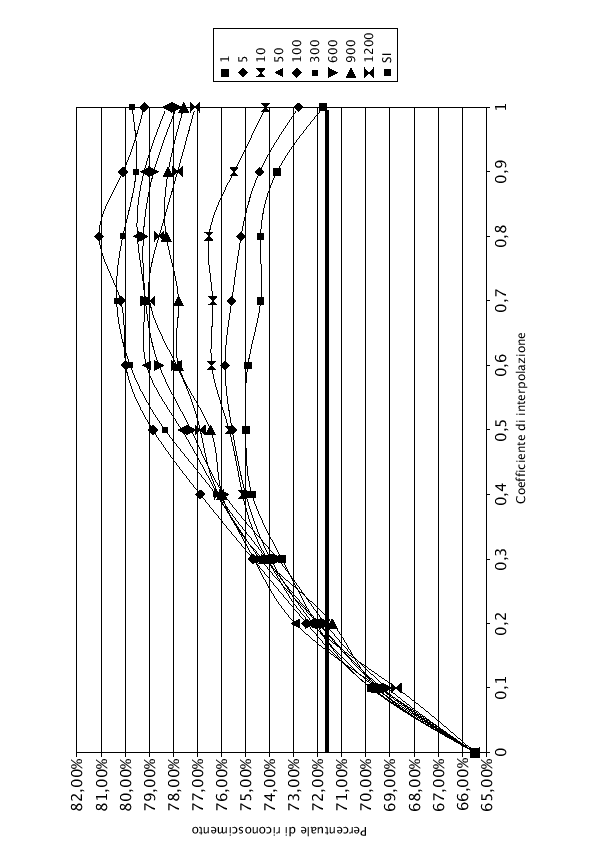
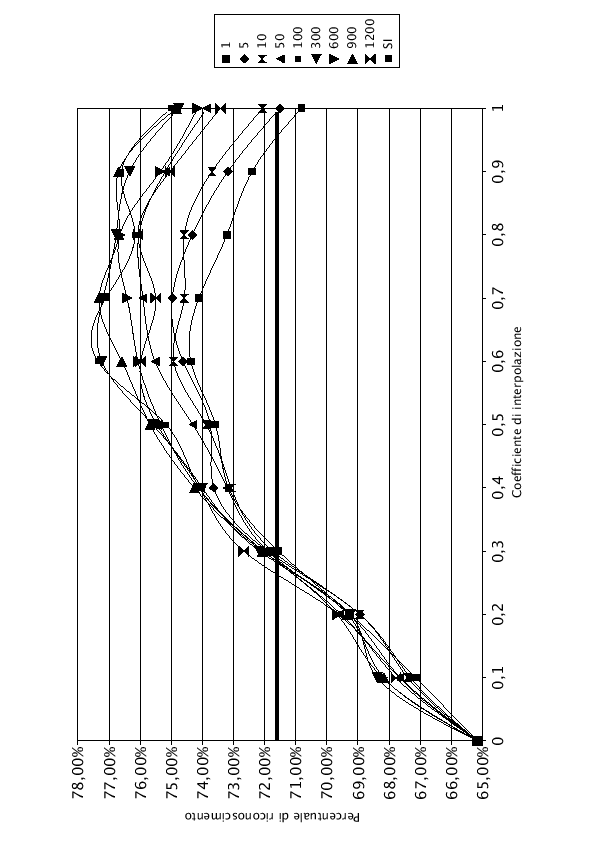
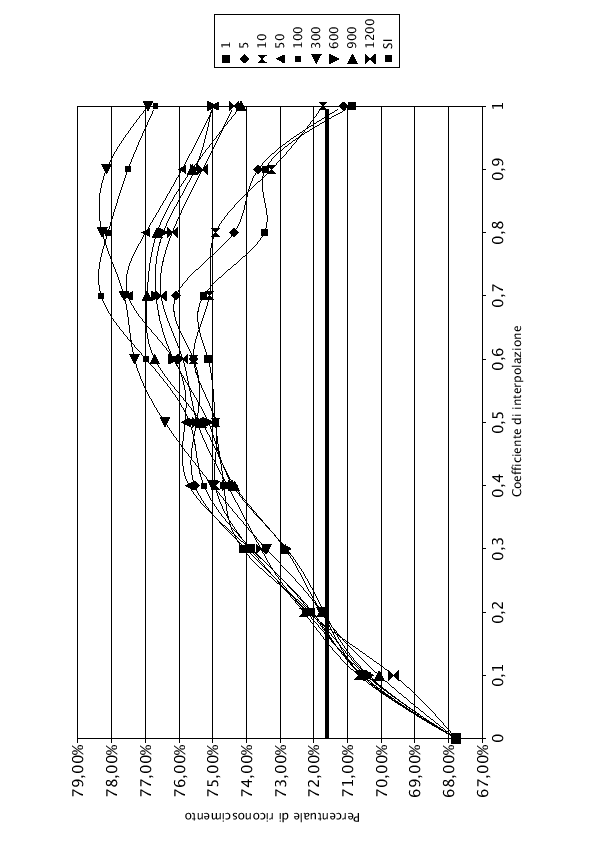
Nelle tabelle (7.1), (7.2) e (7.3) e nei grafici (7.3), (7.4), e (7.5) sono riportati i risultati dell'interpolazione di tutta la rete, di LIN e di J-LIN. Sono stati riportati solo i grafici dell'interpolazione con 1, 5, 10, 50, 100, 300, 600, 900 e 1200 frasi di addestramento del modello SD, per migliorarne la leggibilità.
Osservando i grafici si nota che, per ![]() , anche aumentando il numero di frasi di addestramento dei modelli SD, la percentuale di riconoscimento rimane costante. Questo comportamento è normale, infatti dalla formula che regola l'interpolazione (7.1), con
, anche aumentando il numero di frasi di addestramento dei modelli SD, la percentuale di riconoscimento rimane costante. Questo comportamento è normale, infatti dalla formula che regola l'interpolazione (7.1), con ![]() , si ottiene esattamente la rete AD, che rimane costante in tutto l'esperimento. Pur essendo una rete adattata all'ambiente, la percentuale di riconoscimento è inferiore rispetto al 71.60% fornito dalla rete SI, utilizzando le frasi di test del parlatore DM. Questo comportamento è provocato dall'utilizzo di solo tre parlatori (DM, MA e MG) per adattare la rete, che oltre ad essere adattata all'ambiente è anche adattata ai tre parlatori. Il parlatore DM, che non ha mai contribuito ad addestrare la rete AD, viene perciò riconosciuto male.
, si ottiene esattamente la rete AD, che rimane costante in tutto l'esperimento. Pur essendo una rete adattata all'ambiente, la percentuale di riconoscimento è inferiore rispetto al 71.60% fornito dalla rete SI, utilizzando le frasi di test del parlatore DM. Questo comportamento è provocato dall'utilizzo di solo tre parlatori (DM, MA e MG) per adattare la rete, che oltre ad essere adattata all'ambiente è anche adattata ai tre parlatori. Il parlatore DM, che non ha mai contribuito ad addestrare la rete AD, viene perciò riconosciuto male.
Nel lato destro del grafico, i punti in cui ![]() , si nota che la percentuale di riconoscimento sale all'aumentare delle frasi di addestramento. In accordo con la formula (7.1), con
, si nota che la percentuale di riconoscimento sale all'aumentare delle frasi di addestramento. In accordo con la formula (7.1), con ![]() , si ottengono esattamente i pesi della rete SD, i cui grafici sono noti e studiati accuratamente nel capitolo (5).
, si ottengono esattamente i pesi della rete SD, i cui grafici sono noti e studiati accuratamente nel capitolo (5).
Tutti i grafici hanno un comportamento simile. Durante le prime frasi di addestramento hanno un andamento curvilineo con concavità verso il basso, con l'aumentare del numero di frasi di training la concavità si riduce fino ad assumere un andamento monotono crescente.
Come si nota, con poche frasi di addestramento, i valori di ![]() e di
e di ![]() rappresentano due punti di minimo. Facendo variare il coefficiente di interpolazione
rappresentano due punti di minimo. Facendo variare il coefficiente di interpolazione ![]() , si migliora la qualità del riconoscimento. Esiste un punto di massimo, rappresentato nelle tabelle in grassetto.
Quando il numero di frasi di addestramento cresce, il valore del
, si migliora la qualità del riconoscimento. Esiste un punto di massimo, rappresentato nelle tabelle in grassetto.
Quando il numero di frasi di addestramento cresce, il valore del ![]() massimo si sposta sempre più verso 1, finchè con un numero sufficiente di frasi il modello SD è quello che offre i risultati migliori. Il modello SD, infatti, oltre a conglobare le informazioni del parlatore, impara anche quelle riferite all'ambiente.
massimo si sposta sempre più verso 1, finchè con un numero sufficiente di frasi il modello SD è quello che offre i risultati migliori. Il modello SD, infatti, oltre a conglobare le informazioni del parlatore, impara anche quelle riferite all'ambiente.
La linea orizzontale in grassetto del grafico rappresenta la percentuale di riconoscimento che si sarebbe ottenuta utilizzando per il riconosciemento la rete SI.
Il comportamento di questa tecnica è molto particolare: interpolando due reti che separatamente darebbero risultati peggiori rispetto alla rete SI, si riesce ad ottenere una rete che funziona meglio. In pratica si riescono ad unire, in un unica rete, sia i pregi di un adattamento all'ambiente, sia l'informazione acquisita da un adattamento rapido al parlatore.
Analizzando le prestazioni con un'unica frase di adatattamento del modello SD rispetto alla rete SI si vede come la strategia con risultati migliori è l'adattamento di tutta la rete, con un miglioramento del 3.02%. J-LIN si attesta sugli stessi livelli dell'adattamento di tutta la rete, con un miglioramento del 2.94%, mentre LIN va decisamente peggio con un miglioramento solo del 1.60%.
In generale LIN ha prestazioni, con qualsiasi numero di frasi di adattamento, peggiori rispetto a tutte le altre strategie. Per poche frasi di adattamento, fino a 100, J-LIN ha prestazioni spesso migliori, comunque paragonabili all'adattamento di tutta la rete.
Con un numero elevato di frasi di addestramento, invece, prevale l'adattamento di tutta la rete. Con tante frasi il ![]() ottimo tende a 1, facendo prevalere il comportamento della rete SD. Come analizzato nel capitolo (5), con molte frasi la tecnica che ottiene risultati migliori è l'adattamento di tutta la rete.
ottimo tende a 1, facendo prevalere il comportamento della rete SD. Come analizzato nel capitolo (5), con molte frasi la tecnica che ottiene risultati migliori è l'adattamento di tutta la rete.
Il comportamento dell'adattamento di tutta la rete è leggermente atipico, rispetto ai risultati forniti da LIN e J-LIN. Il valore del ![]() massimo, anzichè crescere con il numero di frasi di addestramento, non riesce mai ad arrivare a 1 ed ha un andamento piuttosto irregolare.
Questo comportamento imprevisto, è dovuto al fatto che non si può applicare la tecnica di interpolazione dei pesi in modo esatto ad un rete a più livelli con funzione di trasferimento dei neuroni non lineare. Interpolando i pesi del livello di ingresso della rete si modifica l'output del primo livello di neuroni. Questo procedimento è consentito nel caso di LIN e J-LIN, poichè si compie un'interpolazione tra neuroni con funzione di trasferimento lineare. Entrambi i modelli da interpolare eseguono una trasformazione sui parametri di ingresso, fornendo valori coerenti con la struttara della rete SI soprastante. Eseguendo l'interpolazione si ottengono valori di peso compresi tra i pesi della rete AD e i pesi della rete SD, che sono ancora un buon input per la rete SI.
massimo, anzichè crescere con il numero di frasi di addestramento, non riesce mai ad arrivare a 1 ed ha un andamento piuttosto irregolare.
Questo comportamento imprevisto, è dovuto al fatto che non si può applicare la tecnica di interpolazione dei pesi in modo esatto ad un rete a più livelli con funzione di trasferimento dei neuroni non lineare. Interpolando i pesi del livello di ingresso della rete si modifica l'output del primo livello di neuroni. Questo procedimento è consentito nel caso di LIN e J-LIN, poichè si compie un'interpolazione tra neuroni con funzione di trasferimento lineare. Entrambi i modelli da interpolare eseguono una trasformazione sui parametri di ingresso, fornendo valori coerenti con la struttara della rete SI soprastante. Eseguendo l'interpolazione si ottengono valori di peso compresi tra i pesi della rete AD e i pesi della rete SD, che sono ancora un buon input per la rete SI.
Nel caso dell'interpolazione di tutta la rete, invece, il primo livello come i successivi utilizzano una funzione di trasferimento non lineare: la sigmoide. Modificando i pesi tramite l'interpolazione, il valore di uscita dei neuroni del primo livello non sarà più linearmente dipendente dalla trasformazione fatta sui pesi. Il valore che sarà propagato ai livelli successivi avrà un errore dovuto alla non linearità della funzione di trasferimento, che verrà amplificato nei livelli successivi. Fortunatamente quest'errore sarà ridotto perchè le due reti, AD e SD, non sono di molto differenti tra di loro.
Un altro errore è tentare di applicare l'interpolazione dei pesi su una rete a più livelli. Interpolando l'ultimo livello della rete, cambiano anche gli input che quel livello dovrebbe avere dai neuroni sottostanti per funzionare correttamente. Nel caso di una rete a più livelli, per agire correttamente, bisognerebbe compiere l'interpolazione partendo dall'ultimo livello fino al primo, ma ad ogni strato di pesi interpolato bisognerebbe riaddestrare sia la rete AD che SD, al fine di trovare i pesi ottimali dei livelli sottostanti, per ottenere un giusto ingresso al livello appena interpolato. Applicare ricorsivamente dal livello di uscita a quello di ingresso l'interpolazione dei pesi è purtroppo un procedimento molto lungo, sicuramente non applicabile in un'applicazione di adattamento veloce.
Nonstante queste imprecisioni, anche l'interpolazione di tutta la rete fornisce un aumento delle prestazioni apprezzabili. Considerando che questo metodo, con un elevato numero di frasi di addestramento, fornisce i risultati migliori, si è deciso di trattarlo, consapevoli delle imprecisioni create dall'interpolazione.
|
Quando il sistema di riconoscimento viene utilizzato da un nuovo parlatore, non è possibile rilevare il coefficiente di interpolazione che offre il risultato migliore. Occorre trovare una legge che, a seguito di alcuni paramentri noti durante l'addestramento, possa fornire il coefficiente ![]() da utilizzare. Sia dai grafici che dalle tabelle appare evidente che esso dipende dal numero di frasi di addestramento del modello SD. Con molta probabilità vi è anche una dipendenza dal parlatore. I nostri esperimenti sono stati fatti sul solo parlatore DM del database italiano, quindi, non è stato possibile analizzare se esiste una dipendenza.
da utilizzare. Sia dai grafici che dalle tabelle appare evidente che esso dipende dal numero di frasi di addestramento del modello SD. Con molta probabilità vi è anche una dipendenza dal parlatore. I nostri esperimenti sono stati fatti sul solo parlatore DM del database italiano, quindi, non è stato possibile analizzare se esiste una dipendenza.
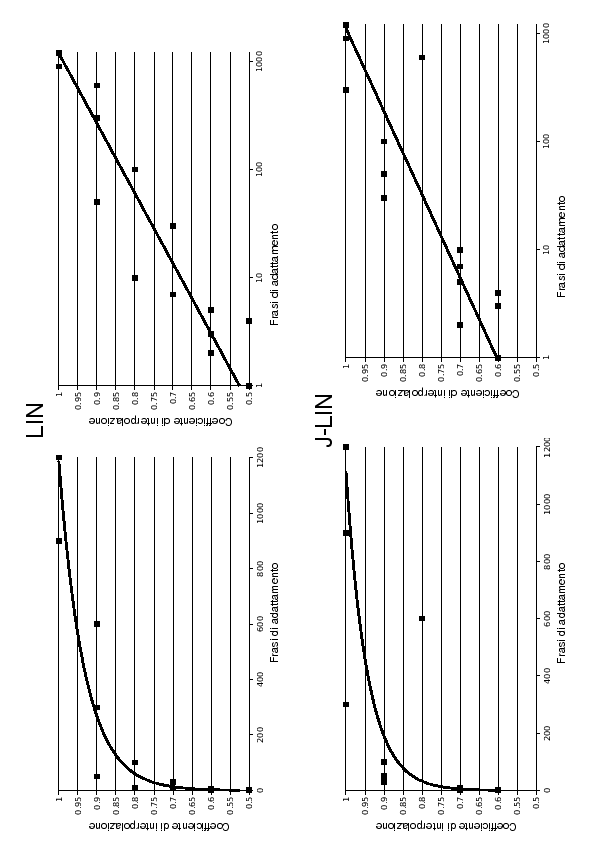
Mettendo in ascissa il numero di frasi di addestramento ed in ordinata il coefficiente di interpolazione ![]() (grafico 7.6), si può constatare un andamento di tipo logaritmico, del tipo:
(grafico 7.6), si può constatare un andamento di tipo logaritmico, del tipo:
Facendo l'interpolazione mediante regressione logaritmica (grafico 7.6), si sono ottenute le seguenti costanti:
|
Come si nota dai grafici (7.6), il valore del coefficiente di interpolazione ![]() è pienamente descrivibile dall'equazione (7.3) commettendo un errore piuttosto basso.
Per quanto riguarda l'interpolazione di tutta la rete, invece, non è possibile trovare una formula che permetta di ricavare il valore del coefficiente di interpolazione perchè, come spiegato, la tecnica di interpolazione applicata su tutta la rete è soggetta a degli errori, che rendono irregolare l'andamento del
è pienamente descrivibile dall'equazione (7.3) commettendo un errore piuttosto basso.
Per quanto riguarda l'interpolazione di tutta la rete, invece, non è possibile trovare una formula che permetta di ricavare il valore del coefficiente di interpolazione perchè, come spiegato, la tecnica di interpolazione applicata su tutta la rete è soggetta a degli errori, che rendono irregolare l'andamento del ![]() ottimo.
ottimo.
|
|
|
|
|
|
Nelle tabelle (7.5), (7.6), (7.7) e nei grafici (7.7), (7.8), (7.9) sono riportati i risultati per l'interpolazione di tutta la rete, di LIN e di J-LIN.
Analizzando l'andamento dei coefficienti di interpolazione in cui la percentuale di riconoscimento è maggiore, riportati nelle tabelle in grassetto, si nota un andamento diverso rispetto all'interpolazione applicata per 10 epoche.
Nell'interpolazione di tutta la rete, i coefficienti di interpolazione ottimali, hanno un andamento molto irregolare, anche se si nota un aumento del valore di ![]() ottimo al crescere del numero di frasi di adattamento. Come spiegato la strategia applicata su tutta la rete non può essere un valido metro di misura a causa dell'inapplicabilità, in modo esatto, della tecnica di interpolazione.
ottimo al crescere del numero di frasi di adattamento. Come spiegato la strategia applicata su tutta la rete non può essere un valido metro di misura a causa dell'inapplicabilità, in modo esatto, della tecnica di interpolazione.
Il coefficiente di interpolazione ottimo per LIN e J-LIN rimane praticamente costante a ![]() , all'aumentare del numero di frasi di adattamento. L'addestramento ad 1 epoca non è sufficiente ad ottenere dei modelli SD abbastanza accurati. Un'intepolazione con il modello AD, addestrato in modo robusto con 10 epoche, permette alla rete di ottenere prestazioni migliori rispetto all'utilizzo del solo modello SD. Questo comportamento è anche molto visibile dai grafici, in cui a 1200 frasi si vede che il comportamento non è una curva monotona crescente, come accadeva per 10 epoche.
, all'aumentare del numero di frasi di adattamento. L'addestramento ad 1 epoca non è sufficiente ad ottenere dei modelli SD abbastanza accurati. Un'intepolazione con il modello AD, addestrato in modo robusto con 10 epoche, permette alla rete di ottenere prestazioni migliori rispetto all'utilizzo del solo modello SD. Questo comportamento è anche molto visibile dai grafici, in cui a 1200 frasi si vede che il comportamento non è una curva monotona crescente, come accadeva per 10 epoche.
Se il coefficiente di interpolazione non dipende dal parlatore, questa è una situazione molto favorevole per la realizzazione pratica di questa teoria. Difatti, sapendo già il coefficiente di interpolazione, non esiste più il problema di doverlo approssimare con una funzione, ottendo una semplificazione realizzativa della tecnica.
I grafici mostrano tutti l'andamento tipico della tecnica: una curva con la concavità rivolta verso il basso e con minimi posti in corrispondenza delle reti SD e AD. Si è ottenuto un aumento delle prestazioni, rispetto alla rete SI, del 3.39% nel caso dell'adattamento di tutta la rete, del 2.77% nel caso di LIN e del 3.67% per J-LIN. Con un basso numero di frasi di adattamento, l'addestramento dei modelli SD con una singola epoca, funziona meglio rispetto all'utilizzo di 10 epoche. Anche in questo caso J-LIN risulta essere la tecnica migliore.