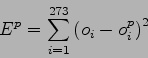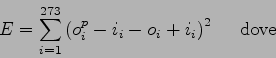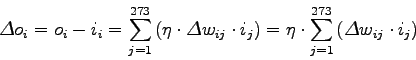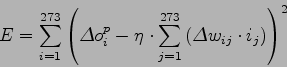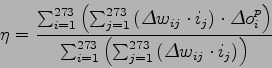Next: 8.2.1 Esperimento di validazione Up: 8. Altre tecniche Previous: 8.1 Addestramento con learning Index
È stata descritta in questa tesi, poichè la teoria su cui basa il suo funzionamento ha dimostrato di essere corretta. Questa tecnica ha diversi pregi. Purtroppo l'incapacità di compiere un passaggio, cioè l'inversione della rete neurale, l'ha resa inapplicabile. Con future ricerche si potrebbero, però, trovare dei metodi che compiono questo passaggio in modo approssimato, permettendone la completa applicabilità. Per modellare le caratteristiche fonetiche dei parlatori si utilizzano anche in questo caso delle LIN.
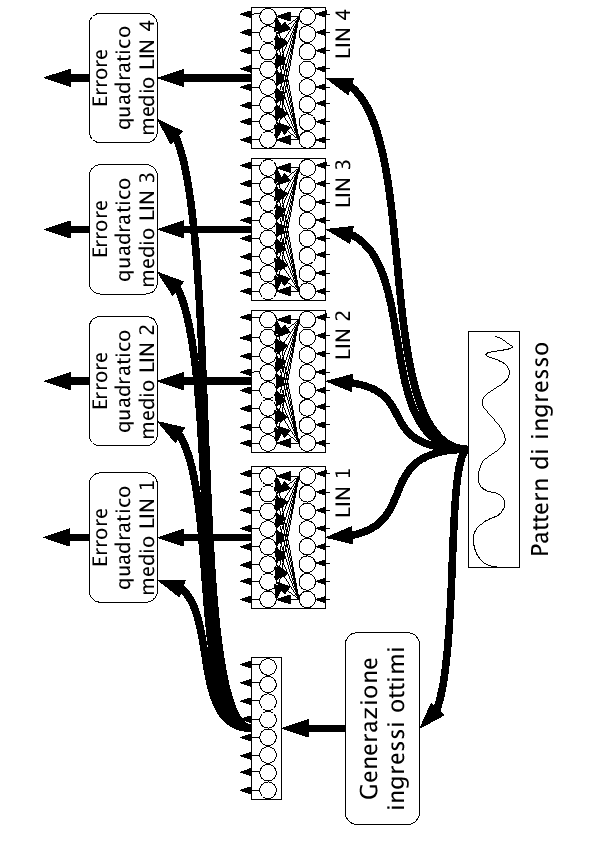
Una LIN effettua una trasformazione lineare sui paramentri di ingresso al fine di renderli il più possibile simili agli ingressi che si aspetterebbe la rete SI per quel determinato fonema. Nel caso venga utilizzata una LIN appartenente ad un parlatore con caratteristiche vocali differenti rispetto a quello giusto, la trasformazione sugli ingressi compiuta dalla LIN, sarà peggiore rispetto all'utilizzo diretto dei pattern di ingresso.
Se è possibile ottenere gli ingressi ottimali, per un determinato target, da fornire alla rete al fine di ottenere il target, si può pensare di fare un confronto tra gli ingressi ottimi e gli ingressi trasformati dalle varie LIN. La LIN che fornirà l'uscita maggiormente simile all'ingresso ottimo della rete, sarà la LIN rappresentativa del parlatore, che verrà scelta per i successivi riconoscimenti.
Come criterio di similitudine si è scelto l'errore quadratico medio tra le 273 uscite di ogni LIN e i 273 ingressi ottimali per la rete SI. Tale scelta, a seguito di una verifica compiuta più avanti in questo capitolo, è risultata ragionevole.
Le LIN devono essere addestrate in modo robusto, con materiale proveniente dallo stesso parlatore. Nei nostri esperimenti si sono addestrate 4 LIN, una per ognuno dei parlatori del database italiano DB-Micro, con 285 frasi e 5 epoche. Si partirà a spiegare questa tecnica nell'ipotesi che sia possibile ottenere gli ingressi ottimi riferiti ad un pattern per la rete SI, successivamente in questo capitolo verrà trattato il problema di come ottenerli. Con lo stesso pattern utilizzato per ricavare gli ingressi ottimi, si può effettuare il run-forward delle LIN riferite ai parlatori, ottenendo una serie di ingressi trasformati dalle LIN (figura 8.2).
Tra gli ingressi trasformati, quelli riferiti alla LIN del parlatore e alle LIN dei parlatori con caratteristiche vocali simili, saranno più simili agli ingressi ottimi, rispetto agli altri.
Sia
![]() l'input ottimo e sia
l'input ottimo e sia
![]() l'output ottenuto dal run-forward della LIN riferita al parlatore
l'output ottenuto dal run-forward della LIN riferita al parlatore ![]() , l'errore quadratico medio sarà:
, l'errore quadratico medio sarà:
Come accennato in precedenza, l'aspetto più difficile di questa tecnica consiste nel trovare gli input ottimi per un determinato pattern. Utilizzando la rete neurale per un normale riconoscimento, con il principio utilizzato nell'addestramento non supervisionato si riesce a ricavare un target. Target con una precisione che oscilla dal 70% all'80%. Un errore del 30% sulla creazione del target fornisce una precisione sufficiente per ottenere dati significativi nella scelta del modello. Il riconoscitore, in ogni caso, fornisce lo score una misura di confidence: quanto è probabile che ciò che è stato riconosciuto sia veritiero. Analizzando solo i pattern con confidence più alta si può abbattere notevolmente l'imprecisione nella creazione dei target.
Una volta ottenuto il target, si possono cercare gli ingressi ottimi per ottenere quel target. Una prima soluzione è stata quella di cercare un metodo che permettesse di invertire l'intera rete neurale. Si è riscontrato che la rete neurale non è invertibile per i seguenti motivi:
Per risolvere il problema si sono cercati dei metodi approssimati. Utilizzando l'algoritmo di back propagation per addestrare una rete, l'unico parametro che è possibile regolare è il learning rate ![]() . Per la LIN di ogni parlatore si è trovato il valore di learning rate
. Per la LIN di ogni parlatore si è trovato il valore di learning rate ![]() , che minimizza l'errore quadratico medio.
Una volta trovato il learning rate ottimo per tutte le LIN, quella con errore quadratico medio minore sarà la vincente.
Sia
, che minimizza l'errore quadratico medio.
Una volta trovato il learning rate ottimo per tutte le LIN, quella con errore quadratico medio minore sarà la vincente.
Sia
![]() l'input ottimo per la rete SI, sia
l'input ottimo per la rete SI, sia
![]() l'output della LIN riferita al parlatore
l'output della LIN riferita al parlatore ![]() e sia
e sia
![]() il pattern di ingresso, l'errore quadratico medio potrà essere scritto nel seguente modo:
il pattern di ingresso, l'errore quadratico medio potrà essere scritto nel seguente modo:
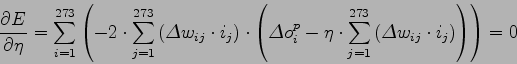 |
Per i calcoli è stata fatta la semplificazione che la LIN sia interamente interconnessa. Nel nostro caso le LIN utilizzate sono connesse a blocchi:
![]() di formula (8.9) deve essere divisa in 7 sommatorie da 39 elementi, che variano i loro estremi in dipendenza del valore di
di formula (8.9) deve essere divisa in 7 sommatorie da 39 elementi, che variano i loro estremi in dipendenza del valore di ![]() .
Una volta trovati i learning rate ottimi per ogni LIN, si possono inserire nell'equazione (8.7) per trovare l'errore quadratico medio associato ad ogni LIN, ed ottenere la rete con errore minimo.
.
Una volta trovati i learning rate ottimi per ogni LIN, si possono inserire nell'equazione (8.7) per trovare l'errore quadratico medio associato ad ogni LIN, ed ottenere la rete con errore minimo.
A seguito dell'implementazione pratica dell'architettura descritta, si è potuto constatare che il metodo di determinazione degli ingressi ottimi non riesce a fornire, con sufficiente precisione, gli ingressi al fine di ottenere il target desiderato. I parlatori vengono riconosciuti in modo quasi casuale. L'algoritmo di back propagation tende, infatti, a minimizzare il gradiente dell'errore rispetto al target, compiuto durante il riconoscimento. Non è un metodo esatto, esso abbassa l'errore ad ogni pattern, minimizzandolo progressivamente. Anche andando a cercare il valore di ![]() ottimo, l'algoritmo non è sufficientemente preciso per fornire, con un solo pattern di ingresso, un valore accurato.
Purtroppo in questa tecnica, rimane aperto il problema di come trovare l'ingresso ottimale per un determinato target.
ottimo, l'algoritmo non è sufficientemente preciso per fornire, con un solo pattern di ingresso, un valore accurato.
Purtroppo in questa tecnica, rimane aperto il problema di come trovare l'ingresso ottimale per un determinato target.
Essa è stata descritta in questa tesi per l'indubbio vantaggio di essere molto veloce: