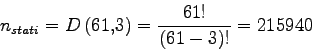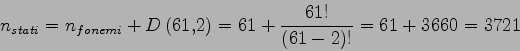Next: 4.3 Programma di addestramento Up: 4. Ambiente utilizzato Previous: 4.1 Rete neurale: topologie Index
Nell'atoma a stati sinistra-destra una possibile ed intuitiva soluzione consiste nel modellare ogni fonema con un singolo stato. Nella realtà questo approccio e alquanto impreciso. I fonemi, nel parlato comune, vengono pronunciati in modo diverso, dipendentemente dai fonemi che li seguono e li precedono: sono perciò dipendenti dal contesto (context dependent).
Una soluzione molto utilizzata è quella dei trifoni in cui ad ogni fonema sono associati 3 stati. Volendo ad esempio modellare la parola ``luna'' e facendo l'ipotesi, per semplificazione, che i fonemi che la compongono siano @, l, u, n, a dove @ rappresenta il silenzio, con il modello fonetico dei trifoni si potrà scrivere come: ``@-l-u l-u-n u-n-a n-a-@''.
Questa modellazione fornisce degli ottimi risultati ma è condizionata dal fatto che per l'addestramento deve avere un elevato numero di materiale di training che sia in grado di coprire tutte le possibili combinazioni di trifoni. Nella realtà tutto questo materiale è raramente disponibile e nel caso delle reti neurali lo squilibrio tra il numero di esempi presenti per i vari trifoni porta in molte casi a penalizzare quelli visti di meno.
Non è nemmeno da sottovalutare l'aumento notevole di dimensione della rete che porta ad un significativo peggioramento delle prestazioni come tempo di riconoscimento e di addestramento.
Analizzando la lingua inglese e utilizzando una modellazione di 61 fonemi come quella da noi utilizzata, otteniamo che il numero di trifoni corrisponde alla disposizione di 61 elementi in gruppi di 3:
Nel 1995 è stata proposta una modellazione ibrida in cui vengono utilizzate delle nuove un unità, le unità transizionali[[21]].
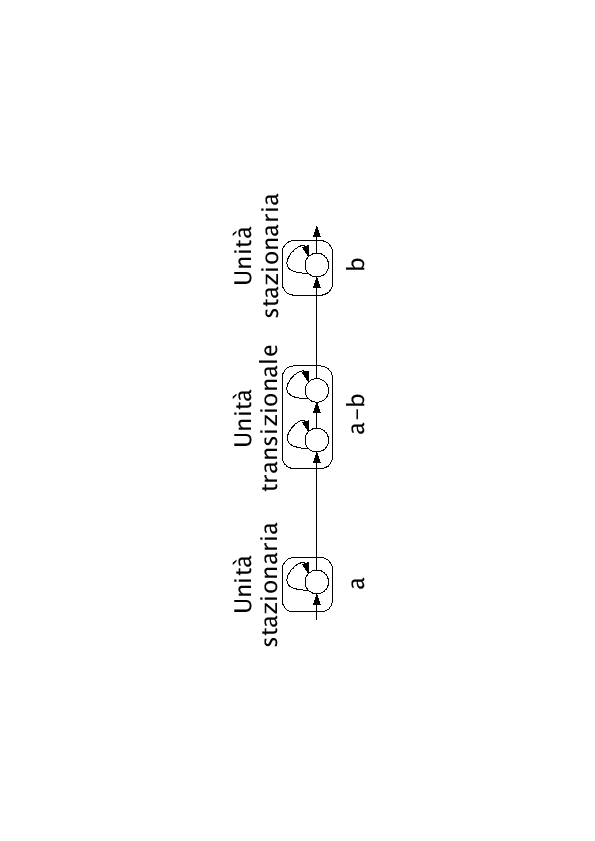
In questa modellazione sono presenti due tipi di unità: le unità stazionarie e le unità transizionali(figura 4.3). Le unità stazionarie hanno il compito di modellare quella parte dei fonemi indipendente dal contesto, cioè sempre uguale indipendentemente dal fonema che lo segue o lo precede. Esse vengono modellate con uno stato. Le unità transizionale servono invece per modellare la transizione tra un unità stazionaria e la successiva. Esse vengono modellate da due stati. Tornando all'esempio della parola ``luna'' e ipotizzando sempre di utilizzare come unità fonetiche @, l, u, n, a, con l' utilizzo delle unità transizionali sarà scritta nel seguente modo: ``@ @-l l l-u u u-n n n-a a a-@ @'' In questo caso il numero di stati sono decisamente inferiori:Nonostante i 3721 stati siano decisamente ridotti rispetto al modello con i trifoni, rimangono pur sempre in numero elevato da addestrare e ingrandiscono in modo deciso la dimensione della rete neurale. È prassi riunire le unità transizionali maggiormente confondibili in classi. Facendo in questo modo il numero di uscite della rete diminuisce notevolmente e il modello diventa più addestrabile.
Nel nostro caso, per la lingua inglese, si è deciso di utilizzare 45 fonemi.
I 45 fonemi da noi utilizzati per l'inglese sono:
``. Ii i Ei e Ae Aa Ou Oa Ah Uu u Eh Or Ai Oi Dz Ts h Au N p b m w f v Th Dh t d n s z $ Zg T$ Dg j l r k g R Dt''
Mentre i 27 utilizzati per l'italiano sono:
`` @ p R o n u t& l e f a s z i g t k dz d m N v dZ b L & x ''
Apportando dei raggruppamenti nelle unità transizionali si sono ottenute 904 classi per l'inglese e 656 per l'italiano.