Next: 6.2.2 Esperimenti effettuati Up: 6.2 K-LIN ottimizzata Previous: 6.2 K-LIN ottimizzata Index
|
Una soluzione ottima esiste e consiste nel effettuare il run-forward separatamente per ogni LIN. Quindi utilizzare una struttura K-LIN, si può ricavare quale sia la LIN che fornisce l'errore minimo rispetto al target ed utilizzare questa LIN per riconoscere le successive frasi del parlatore. Sicuramente questa è la soluzione ottima, ma risente di una elevata pesantezza computazionale: bisogna fare il run-forward per ogni LIN,.
Andando ad analizzare una possibile tecnica approssimata per la soluzione del problema, si è deciso di eliminare la matrice identità e di effettuare il run-forward combinato delle LIN dei vari parlatori.
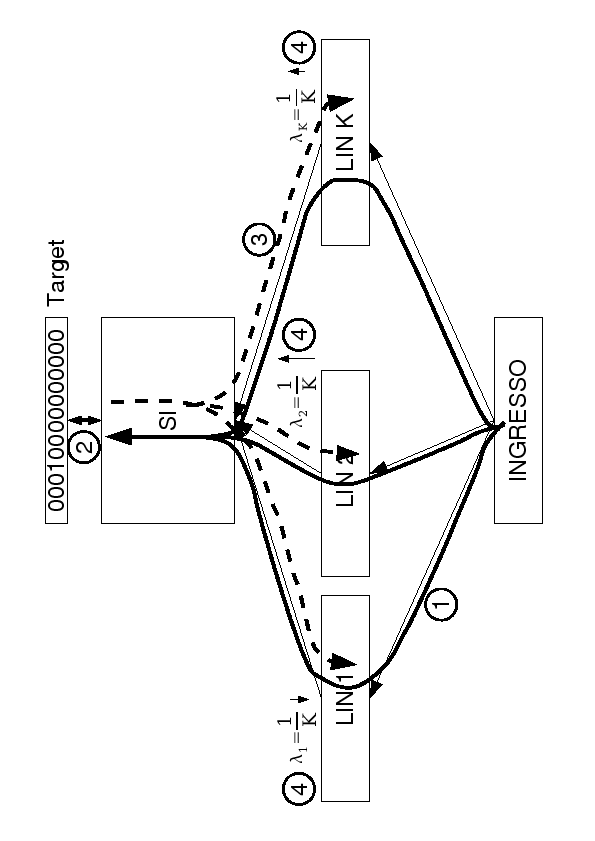
Il collegamento delle LIN alla rete SI rimane invariato ed è schematizzato in figura (6.2).
La vera modifica, oltre all'assenza della LIN identità, consiste in una diversa inizializzazione del valore dei parametri ![]() che collegano le LIN con la rete SI.
Si inizializzano tutto i valori di
che collegano le LIN con la rete SI.
Si inizializzano tutto i valori di
![]() in modo da propagare il valor medio tra ognuna delle 273 uscite delle
in modo da propagare il valor medio tra ognuna delle 273 uscite delle ![]() LIN.
A tal fine sono stati inizializzati a
LIN.
A tal fine sono stati inizializzati a ![]() i valori di tutti i
i valori di tutti i ![]() . Siano
. Siano
![]() gli input della rete SI e
gli input della rete SI e
![]() gli output della LIN
gli output della LIN ![]() -esima, il valore propagato all'ingresso della rete SI è dato da:
-esima, il valore propagato all'ingresso della rete SI è dato da:
Le LIN sono state addestrate esattamente con i parametri utilizzati in sezione 6.1.2.
La modifica più significativa è stata effettuata nei parametri utilizzati per il riconoscimento, in particolare il parametro batchsize, anzichè essere impostato ad epoche, è stato posto a 1. L'aggiornamento del valore dei ![]() , in questo caso, avviene ad ogni pattern. Questo è un punto fondamentale che permette, unitamente al fatto che l'algoritmo di back propagation viene utilizzato sull'errore generato dalle LIN stesse, di ottenere ottimi miglioramenti.
A seguito del primo pattern, se il riconoscimento è effettuato in modo corretto, il valore del
, in questo caso, avviene ad ogni pattern. Questo è un punto fondamentale che permette, unitamente al fatto che l'algoritmo di back propagation viene utilizzato sull'errore generato dalle LIN stesse, di ottenere ottimi miglioramenti.
A seguito del primo pattern, se il riconoscimento è effettuato in modo corretto, il valore del ![]() riferito alla LIN corretta viene alzato, tutti gli altri abbassati. Questo procedimento viene iterato ad ogni pattern dato in ingresso alla rete. Dopo un numero sufficiente di patterns, il
riferito alla LIN corretta viene alzato, tutti gli altri abbassati. Questo procedimento viene iterato ad ogni pattern dato in ingresso alla rete. Dopo un numero sufficiente di patterns, il ![]() della LIN riferita al parlatore, avrà un valore più elevato rispetto alle altre LIN. In questa situazione, il valore propagato durante il run-forward, non è più il valor medio delle varie LIN, ma sarà composto per la maggior parte dalla LIN riferita al parlatore. Se si riesce a raggiungere questa condizione, la percentuale di riconoscimento sarà di gran lunga migliore rispetto a una situazione in cui tutti i
della LIN riferita al parlatore, avrà un valore più elevato rispetto alle altre LIN. In questa situazione, il valore propagato durante il run-forward, non è più il valor medio delle varie LIN, ma sarà composto per la maggior parte dalla LIN riferita al parlatore. Se si riesce a raggiungere questa condizione, la percentuale di riconoscimento sarà di gran lunga migliore rispetto a una situazione in cui tutti i ![]() hanno lo stesso valore.
hanno lo stesso valore.
Stefano Scanzio 2007-10-16
