Next: 6.1.3 Esperimenti effettuati Up: 6.1 K-LIN con matrice Previous: 6.1.1 Struttura Index
Il training, in accordo con l'interpretazione appena enunciata, viene fatto addestrando una normale LIN con i dati provvenienti da uno stesso parlatore. Questo procedimento viene ripetuto per ![]() parlatori ottenendo perciò una rappresentazione per ognuno di essi.
parlatori ottenendo perciò una rappresentazione per ognuno di essi.
I pesi ottenuti per ogni singola LIN possono a questo punto essere caricati nella struttura K-LIN: nel posto associato alla prima LIN vengono messi i parametri relativi alla LIN identità, mentre nei rimanenti ![]() posti vengono caricati i valori delle LIN appena addestrate.
I parametri
posti vengono caricati i valori delle LIN appena addestrate.
I parametri ![]() dello strato di collegamento tra il livello LIN e l'input della rete sono inizializzati a 1 per i valori riferiti alla LIN identità, a 0 nei rimanenti casi. I bias del livello di ingresso della rete SI sono posti a 0.
dello strato di collegamento tra il livello LIN e l'input della rete sono inizializzati a 1 per i valori riferiti alla LIN identità, a 0 nei rimanenti casi. I bias del livello di ingresso della rete SI sono posti a 0.
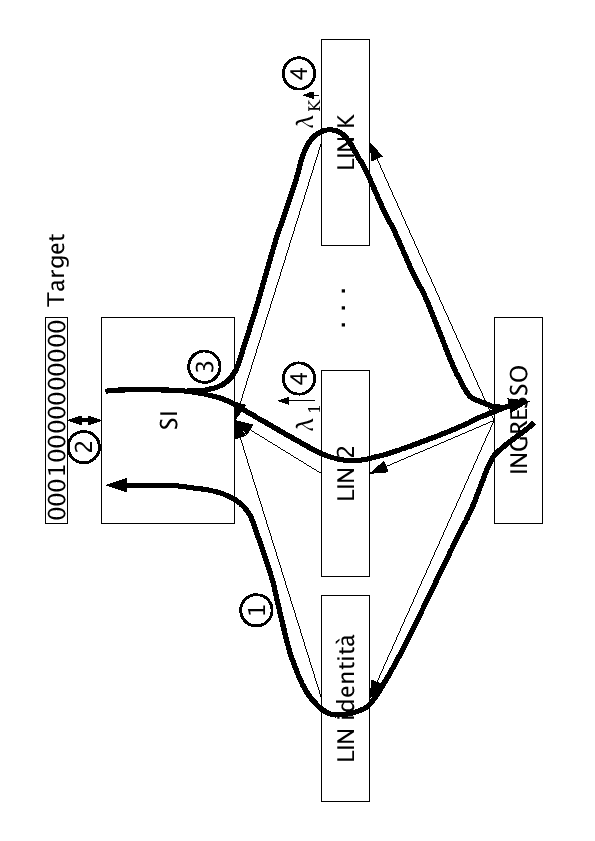
Questa diversa inizializzazione dei ![]() è stata fatta al fine di compiere un run-forward come se esistesse solo la rete SI. Infatti dando un pattern in ingresso viene compiuto il run-forward su tutta la K-LIN, il pattern viene propagato su tutte quante le
è stata fatta al fine di compiere un run-forward come se esistesse solo la rete SI. Infatti dando un pattern in ingresso viene compiuto il run-forward su tutta la K-LIN, il pattern viene propagato su tutte quante le ![]() LIN. Nel caso della prima non viene fatto nulla, nelle rimanenti
LIN. Nel caso della prima non viene fatto nulla, nelle rimanenti ![]() viene applicata la trasformazione riferita al parlatore per cui è stata addestrata. Pertanto verrà propagato ai livelli superiori solo il valore della LIN identità senza nessuna modifica (
viene applicata la trasformazione riferita al parlatore per cui è stata addestrata. Pertanto verrà propagato ai livelli superiori solo il valore della LIN identità senza nessuna modifica (![]() ).
Finito il run-forward della rete si ottengono le probabilità di emissione dei vari fonemi e un errore dovuto all'utilizzo della SI per il riconoscimento.
Si nota che il target, al fine di calcolare l'errore, può essere calcolato in modo supervised o unsupervised.
).
Finito il run-forward della rete si ottengono le probabilità di emissione dei vari fonemi e un errore dovuto all'utilizzo della SI per il riconoscimento.
Si nota che il target, al fine di calcolare l'errore, può essere calcolato in modo supervised o unsupervised.
Al fine di minimizzare l'errore compiuto dalla rete SI (o dalla K-LIN) si può applicare l'algoritmo di back-propagation,
|
Stefano Scanzio 2007-10-16