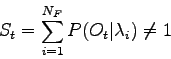2.3.2 Hidden Markov Model
È stata la prima tecnica utilizzata per il riconoscimento vocale e ancor oggi è ampiamente utilizzata. In seguito per completezza ne verrà dato un breve accenno.
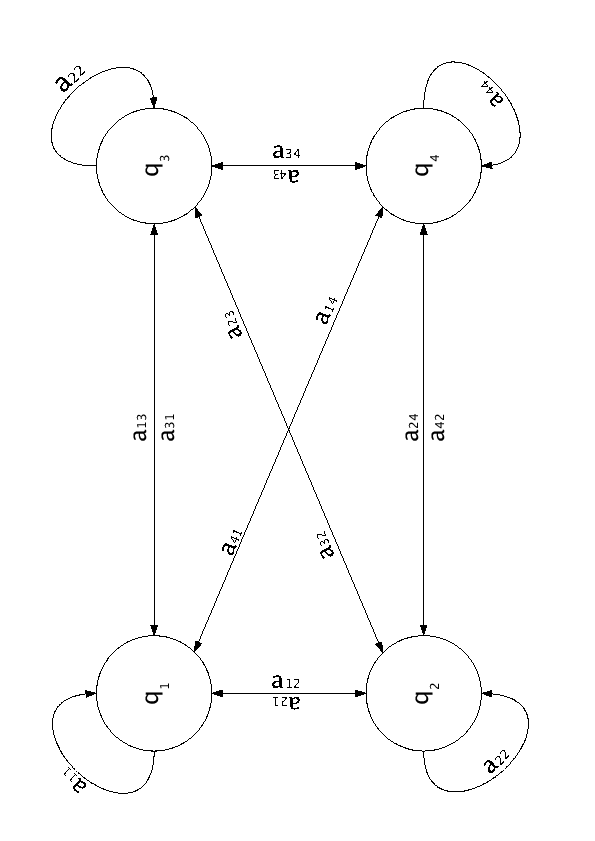
In questo modello si suppone che le varie parole o fonemi evolvano attraverso stati discreti 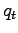 .
.
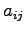 in figura 2.9 rappresenta la probabilità di transizione dallo stato
in figura 2.9 rappresenta la probabilità di transizione dallo stato 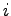 allo stato
allo stato 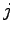 .
Un modello HMM è definito da un insieme di valori
.
Un modello HMM è definito da un insieme di valori 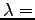 (
(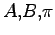 ) dove:
) dove:
La distribuzione di probabilità 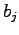 può essere di tipo discreto, semi-continuo o continuo. Nella pratica per rappresentare questa distribuzione di probabilità si usano delle gaussiane. Ce ne sarà una mistura per ogni stato, e ognuna di loro sarà rappresentata da una media e da una varianza. È quindi facile, già a questo punto comprendere, che l'addestramento di un HMM consisterà nel fare variare media e varianza delle varie gaussiane e nel far variare le probabilità di passaggio da uno stato ad un altro.
può essere di tipo discreto, semi-continuo o continuo. Nella pratica per rappresentare questa distribuzione di probabilità si usano delle gaussiane. Ce ne sarà una mistura per ogni stato, e ognuna di loro sarà rappresentata da una media e da una varianza. È quindi facile, già a questo punto comprendere, che l'addestramento di un HMM consisterà nel fare variare media e varianza delle varie gaussiane e nel far variare le probabilità di passaggio da uno stato ad un altro.
Le operazioni da compiere per l'utilizzo del modello e per generare l'output sono le seguenti:
- scegliere uno stato iniziale
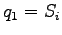 in accordo con
in accordo con 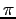 (2.26)
(2.26)
- porre
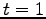
- scegliere
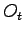 in accordo con la distribuzione
in accordo con la distribuzione 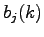 (2.25)
(2.25)
- passare al nuovo stato
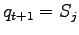 secondo le probabilità di transizione (2.24)
secondo le probabilità di transizione (2.24)
- porre
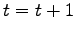 e ritornare al punto (3.) finchè
e ritornare al punto (3.) finchè 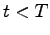 , altrimenti terminare
, altrimenti terminare
Quindi, riassumendo, il sistema durante il riconoscimento evolve attraverso una serie di stati, regolato dalle formule (2.24), (2.25), (2.26).
Figure 2.9:
Diagramma stati transizioni
|
|
Per un corretto funzionamento del modello e quindi per poterlo utilizzare nelle applicazioni reali, ci sono ancora tre problemi da risolvere:
- data una sequenza di simboli osservati
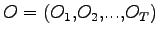 e un modello
e un modello
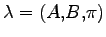 come calcolare la probabilità di osservare la sequenza
come calcolare la probabilità di osservare la sequenza 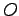 dato il modello, cioè
dato il modello, cioè 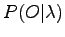
- con
, sequenza di simboli osservati, scegliere la seguenza ottima di stati
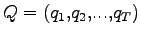 che possa averla generata
che possa averla generata
- come ristimare i parametri relativi al modello per rendere massima
Per risolvere questi problemi, daremo solo riferimento agli algoritmi usati, senza andare nei particolari del loro funzionamento: per trovare si utilizza l'algoritmo Forward-Backward; per trovare la seguenza ottima di stati che possa aver generato una determinata osservazione si utillizza iterativamente l'algoritmo di Viterbi; per ristimare i parametri dei modelli si usano le statistiche calcolate dall'algoritmo di Viterbi e dall'algoritmo di Forward-backward per far convergere la stima ad un ottimo locale.
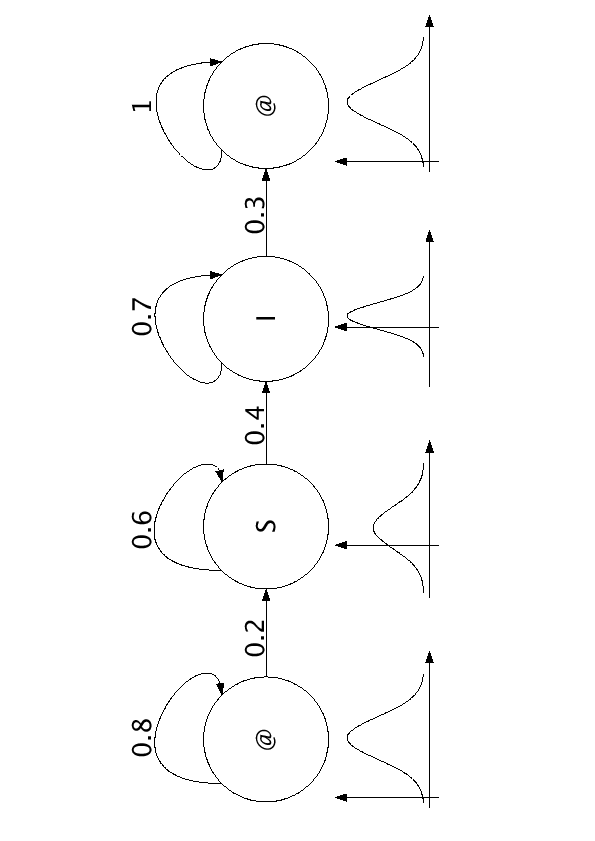
Per finire la trattazione sull'Hidden Markov Model, forniamo un piccolo disegno che esemplifica la modellazione della parola "SI" (figura 2.10).
Figure 2.10:
Esempio di modellazione della parola "SI con HMM"
|
|
Come vediamo il modello è interamente rappresenteto dalle probabilità di transizione da uno stato ad una altro, e dai valori che assumono le distribuzioni di probabilità di emissione degli stati.
Il simbolo @ rappresenta il fonema silenzio che di solito costituisce sempre l'inizio e la fine di un modello.
È interessante notare che la probabilità che l'algoritmo dia come risultato un determinato fonema, dipende sia dalla distribuzione associata a quel fonema sia dallo stato in cui si trova il sistema in quel determinato momento.
Uno dei più grandi difetti dell'Hidden Markov Model consiste nel fatto che i fonemi non vengono addestrati in modo discriminante. Infatti facendo la somma delle probabilità di un osservazione, dato il modello relativo ad un fonema, si ottiene un risultato diverso da 1.
Per essere più chiari:
dove 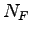 rappresemta il numero di fonemi.
I modelli Markoviani sono classificanti: per ogni fonema viene salvata una mistura di gaussiane che rappresentano la probabilià di trovarsi in quel determinato stato. Tutto il materiale di addestramento relativo a quel determinato fonema viene utilizzato per addestrare il modello ad esso relativo. Si otterranno modelli separati per ogni fonema, che faranno fatica a funzionare correttamente nel caso di suoni confondibili, cioè che danno risultati buoni su più modelli.
Le reti neurali risolvono il problema. Una rete neurale è discriminante: viene addestrata con esempi di tutti i possibili fonemi e riesce in tal modo a dare risultati migliori, rispetto ai modelli Markoviani, su quei fonemi tra di loro più confondibili.
rappresemta il numero di fonemi.
I modelli Markoviani sono classificanti: per ogni fonema viene salvata una mistura di gaussiane che rappresentano la probabilià di trovarsi in quel determinato stato. Tutto il materiale di addestramento relativo a quel determinato fonema viene utilizzato per addestrare il modello ad esso relativo. Si otterranno modelli separati per ogni fonema, che faranno fatica a funzionare correttamente nel caso di suoni confondibili, cioè che danno risultati buoni su più modelli.
Le reti neurali risolvono il problema. Una rete neurale è discriminante: viene addestrata con esempi di tutti i possibili fonemi e riesce in tal modo a dare risultati migliori, rispetto ai modelli Markoviani, su quei fonemi tra di loro più confondibili.
Stefano Scanzio
2007-10-16