Next: 5.2.3 Variando il numero Up: 5.2 Esperimenti Previous: 5.2.1 Riconoscimento in funzione Index
|
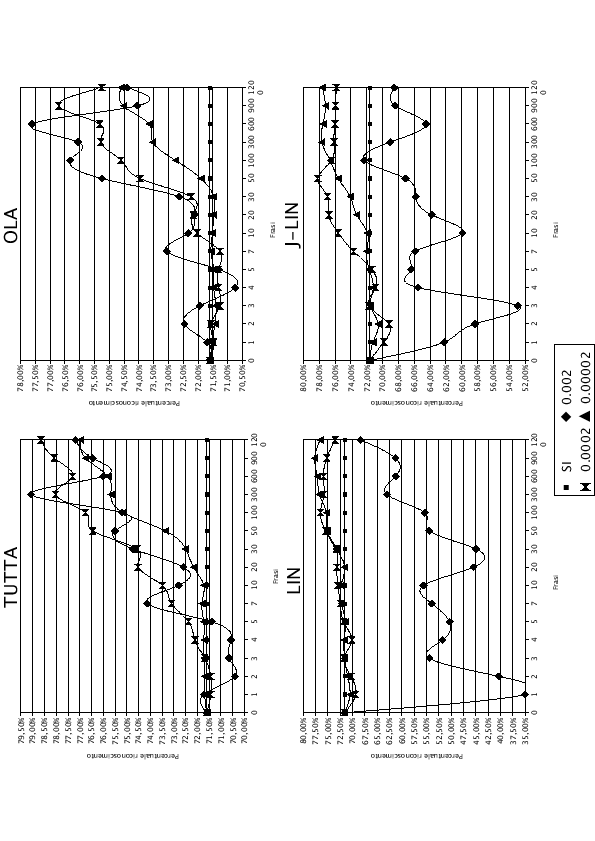
Andando ad analizzare i risultati di tabella (5.2) e dei grafici (5.6) si nota subito che un learning-rate troppo elevato (0.002) provoca effetti dannosi su quasi tutte le tecniche di adattamento analizzate. L'unica a trarne giovamento è la OLA, in cui la maggior parte dei punti con learning-rate di 0.002 si colloca al di sopra dei punti degli altri due esperimenti. Nonostante questo miglioramento OLA rimane al di sotto delle altre tecniche.
Un learning rate elevato provoca oscillazioni pronunciate nei valori della percentuale di riconoscimento portando, nel caso di LIN e J-LIN, a risultati molto peggiori rispetto alla SI. Questo comportamento è imputabile al fatto che vengono compiuti spostamenti sui pesi troppo elevati, che rendono la rete ottima a riconoscere le frasi che sono state appena addestrate, ma la allontanano da un punto di funzionamento medio per ogni tipo di frase. In quelle strategie in cui il numero di pesi è minore, la LIN e la J-LIN, quest'effetto è ancora più evidente.
Un learning-rate minore favorisce un miglioramento progressivo a tutte le tecniche di addattamento. Per quanto riguarda l'adattamento di tutta la rete e la strategia OLA, il learning-rate a 0.00002 porta ad un peggioramento delle prestazioni su qualsiasi numero di frasi di training. Si può notare anche un ritardo del momento in cui le prestazioni della rete adattatata superano quelle della SI: di 16 frasi per l'adattamento di tutta la rete e di 40 frasi per OLA. Nonostante ciò è prevedibile che con l'aumentare del numero di epoche di addestramento la strategia di un learning-rate minore possa essere più efficace. Nel caso di LIN e J-LIN valgono i discorsi fatti in precedenze, con l'aggiunta del fatto che dopo 300 frasi l'esperimento con learning-rate più basso fornisce risultati migliori. Questo dato fornisce un indicazione su come sia più efficiente per queste due tecniche un addestramento con learning-rate basso.
La J-LIN, fino alle 50 frasi, con un learnig-rate di 0.0002, ha un miglioramento molto pronunciato. Nel caso in cui si voglia compiere un adattamento veloce al parlatore, sarebbe possibile utilizzare un learning-rate di 0.0002 per le prime prime 50 frasi, per poi abbassarlo a 0.00002, sfruttando i benefici di entrambe le soluzioni.
Stefano Scanzio 2007-10-16