Next: 8.2 Riconoscimento della LIN Up: 8. Altre tecniche Previous: 8. Altre tecniche Index
Durante l'addestramento una rete neurale tende a polarizzarsi, cioè ad avere una buona percentuale di riconscimento, sui pattern che sono stati visti per ultimi e che sono stati addestrati più volte. Questo processo, che prende il nome di catastrofic forgetting, tende a far perdere la capacità della rete di riconoscere bene i pattern poco addestrati.
A seguito di tale problema si è deciso di compiere un'analisi del movimento dei pesi durante l'addestramento. Analizzando le variazioni dei pesi dell'ultimo strato, si è visto che l'algoritmo di back propagation tende ad alzare i pesi che contribuiscono ad ottenere il valore del nodo riferito al target, e ad abbassare tutti gli altri. Del resto l'algoritmo di back propagation tende a minimizzare il gradiente dell'errore ottenuto rispetto al target, indipendentemente da quanto questa variazione di pesi possa penalizzare il riconoscimento dei pattern associati ad altri target.
Questo scenario mette in evidenza che, per ottenere buoni risultati nell'addestramento di una rete neurale, bisogna utilizzare pattern che coprano, in numero uguale, tutti i possibili target. I pattern dovranno essere addestrati in sequenze casuali: infatti se si utilizzano lunghe sequenze di pattern riferiti allo stesso target, la rete si sposterà troppo verso quel target. Al pattern successivo si sposterà completamente verso un altro target, facendo oscillare i pesi da un target ad un altro e perdendo in capacità discriminativa.
Sfortunatamente, nella realtà, non è sempre possibile avere un numero sufficiente di pattern per addestrare tutta la rete e per coprire con lo stesso numero di pattern tutti i target.
Ad esempio, analizzando il caso di una rete neurale per il riconoscimento vocale ed in specifico la rete inglese, ci sono 949 unità di output. Per riuscire ad evitare il più possibile il sovra-addestramento di un target, si utilizzano delle frasi foneticamente bilanciate. Esse hanno lo scopo di riuscire a coprire, nel modo più uniforme possibile, tutti i fonemi utilizzati per il riconoscimento. Un compito arduo per due motivi:
Questa tecnica ha perciò applicabilità tutte le volte in cui i patterns riferiti ai vari target della rete non sono in numero uguale.
Riprendendo il meccanismo di addestramento di una rete neurale tramite l'algoritmo di back propagation, la formula che regola la variazione dei pesi è:
Il learning rate può influenzare in modo drastico la capacità di apprendimento di una rete neurale. Nel caso sia troppo elevato viene amplificato il catastrofic forgetting e si ottiene una rete con pesi oscillanti che tendono ad imparare solamente le ultime cose dette. Nel caso di un learning rate troppo basso, invece, la rete apprende molto lentamente e in alcuni casi i pesi possono rimanere bloccati in un minimo locale della funzione di errore, impedendone un ulteriore movimento. L'algoritmo di back propagation suggerisce uno spostamento al fine di minimizzare l'errore quadratico medio tra ciò che è riconosciuto e il target. L'entità di questo spostamento viene regolata dal learning rate ![]() .
.
Non è detto che il learning rate debba essere un parametro fisso durante tutto l'addestramento. È infatti una pratica comune quella di far diminure ![]() durante il training, per affinare sempre più le capacità di riconoscimento della rete.
Per affrontare il problema del differente numero di patterns associati ai target della rete, si è agito variando il valore del learning rate durante il training.
durante il training, per affinare sempre più le capacità di riconoscimento della rete.
Per affrontare il problema del differente numero di patterns associati ai target della rete, si è agito variando il valore del learning rate durante il training.
L'idea è quella di riuscire a legare il valore del learning rate al target. In pratica, quando si addestrano i nodi di uscita con molti patterns a loro riferiti, si può utilizzare un learning rate minore. In questo caso, gli spostamenti è meglio che siano piccoli, infatti ci sono molti esempi riferiti a quel target che possono lentamente far convergere la rete al valore ottimale. Quando ci sono pochi patterns riferiti ad un target conviene avere spostamenti più ampi, al fine di riuscire a dare la stessa importanza a questo target rispetto a quelli per i quali ci sono più patterns di addestramento.
Una volta ottenuti i dati sul numero di patterns riferiti ad ogni target, si è studiato come legare questo valore al learning rate.
Una prima ipotesi è stata di ottenere ![]() in modo lineare attraverso la seguente formula:
in modo lineare attraverso la seguente formula:
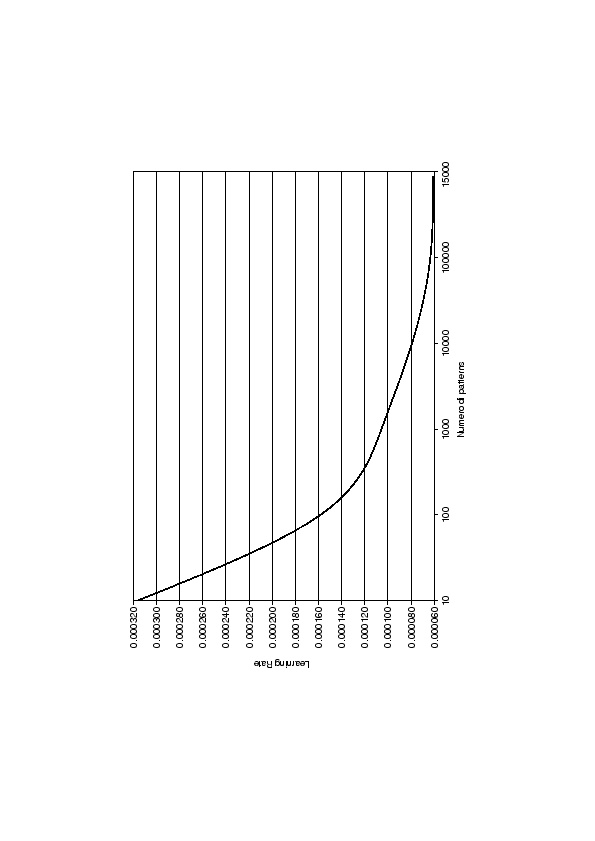
Si è deciso perciò di utilizzare una legge logaritmica, in cui i target con meno esempi sono anche in questo caso addestrati con un learning rate minore, ma non esattamente proporzionale al numero di patterns:
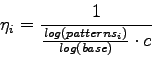 |
(8.3) |
con il parametro ![]() si può regolare la base del logaritmo e decidere quanto deve essere consistente il decremento del learning rate all'aumentare del numero di patterns associati al target
si può regolare la base del logaritmo e decidere quanto deve essere consistente il decremento del learning rate all'aumentare del numero di patterns associati al target ![]() . La costante
. La costante ![]() ha lo stesso significato di formula (8.2).
ha lo stesso significato di formula (8.2).
Il miglioramento rispetto alla tecnica standard di addestramento, quella con batchsize pari a 10, è del 6.94%. Nell'esperimento, come spiegato, è stato utilizzato un batchsize pari a 1. Anche con le tecniche di addestramento standard, si riesce ad ottenere un miglioramento in termini di word accuracy pari al 1.74%. Per un raffronto più equo bisogna quindi confrontare la tecnica con learnig rate variabile rispetto alla tecnica standard con batchsize pari a 1. Il risultato è un miglioramento del 5.20%, un incremento molto significativo nel campo del riconoscimento vocale, che conferma la validità di questa tecnica.
Sebbene questa tecnica non sia prettamente studiata per l'adattamento al parlatore, essa può essere utilizzata tutte le volte in cui ci sia l'esigenza di addestrare una rete e perciò anche quando si hanno a disposizione frasi provvenienti da uno stesso parlatore. In tal caso, si avrà un aumento delle prestazioni di tutte le tecniche di adattamento trattate nei capitoli precedenti, dovuto semplicemente al miglioramento del meccanismo con cui viene addestrata la rete.
Stefano Scanzio 2007-10-16