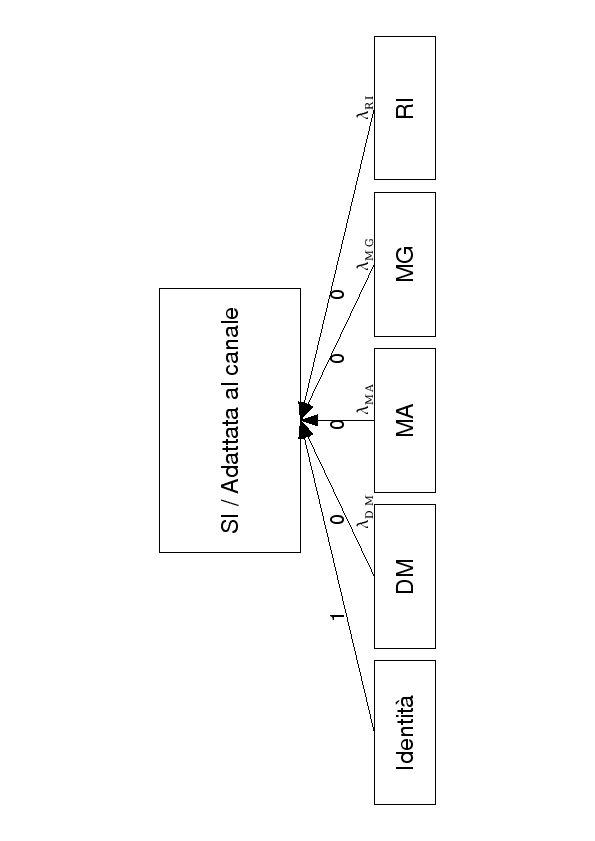
Next: 6.1.4 Considerazioni Up: 6.1 K-LIN con matrice Previous: 6.1.2 Funzionamento Index
Gli esperimenti sono stati compiuti con il database italiano DB-Micro. Si sono addestrate 4 LIN con rispettivamente le prime 285 frasi per il parlatore DM, le seconde 285 per il parlatore MA, le terze 285 per il parlatore MG e le quarte 285 per il parlatore RI. Si è utilizzata questa divisione per fare in modo che nessuna LIN fosse addestrata con frasi uguali. Questo rende più difficile il compito della rete neurale, ma rende l'esperimento più attendibile. Sono state utilizzate 285 frasi anzichè 300 solamente perché al parlatore RI mancavano alcune delle 1200 frasi del training-set. I parametri utilizzati nel file di configurazione di NNA per il riconoscimento del parlatore sono:
Il compito di LIN e di J-LIN in questi esperimenti è quello di riuscire a racchiudere nei loro pesi le informazioni che caratterizzano il parlatore. Si è pensato, per una migliore riuscita dell'esperimento, che sarebbe stato opportuno riuscire ad isolare qualsiasi altra fonte di diversità che non sia quella dei parlatori.
Una rete SI è addestrata con materiare provveniente da molti parlatori e da molte fonti, al fine di funzionare correttamente con il maggior numero di parlatori, nelle condizioni più svariate. Tuttavia, oltre alla differenza tra i parlatori ne esiste anche una dovuta al canale utilizzato per la raccolta del database (microfono, linea telefonica, scheda di acquisizione, eventuale sottocampionamento, compressione a-law,...). Utilizzando tipi diversi di microfoni o tipi diversi di mezzi di trasmissione (doppino telefonico, rete GSM,...), la rete SI non fornisce sempre risultati buoni. Nel nostro caso le frasi registrate per i quattro parlatori italiani sono state ottenute utilizzando un microfono comune per tutti e come mezzo di trasmissione un PABX aziendale. La rete SI utilizzata non è stata addestrata con frasi provvenienti dallo stesso canale dei 4 parlatori. Effettuando l'addestramento di LIN e di J-LIN con la normale rete SI, l'argoritmo di back-propagation tenderà a correggere al fine di ridurre anche l'impatto del canale sulla qualità del riconoscimento. Si è deciso di trasferire le informazioni riguardanti il canale direttamente sulla rete SI. L'adattamento al canale della rete SI è stato fatto addestrando la rete con tutto il materiale di training dei 4 parlatori (4800 frasi), per 10 epoche. Le LIN e le J-LIN sono state poi addestrate, con le rispettive 285 frasi di ogni parlatore, sia utilizzando una rete SI che una rete adattata al canale.
Una volta addestrate le 4 LIN e le 4 J-LIN, per le 2 condizioni di rete SI e di rete adattata al canale, si è passati alla fase di test.
Sono state caricate nella struttura 5-LIN nel ordine di figura (6.4) ed è stata applicata la seguente procedura:
Una volta ricavati i valori di ![]() per tutti i gruppi di 2 frasi per ogni parlatore si è proceduto nel calcolare per ogni parlatore la percentuale di frasi che sono state assegnate, in modo corretto, ad esso e quelle assegnate scorrettamente agli altri parlatori. I risultati sono riportati in tabella (6.2).
per tutti i gruppi di 2 frasi per ogni parlatore si è proceduto nel calcolare per ogni parlatore la percentuale di frasi che sono state assegnate, in modo corretto, ad esso e quelle assegnate scorrettamente agli altri parlatori. I risultati sono riportati in tabella (6.2).
I risultati mostrano chiaramente il buon funzionamento i questa tecnica di riconoscimento del parlatore. Come percentuale non si è mai scesi al di sotto del 70%. Il parlatore DM mostra di essere maggiormente confondibile rispetto agli altri i quali hanno una qualità di riconoscimento sempre maggiore al 95%. In tutte le quattro tipologie di esperimento appare evidende la divisione dei parlatori in due gruppi: (DM,RI) e (MA,MG). In generale, quando una frase del parlatore DM viene riconosciuta in modo erroneo, essa viene assegnata ad RI e lo stesso vale tra i parlatori MA e MG.
Questo comportamento è molto interessante, perchè fa percepire come i valori dei ![]() rappresentino qualcosa che va al di la del semplice riconoscimento di un parlatore, potrebbe anche rappresentare un misura della vicinanza tra i parlatori. Andando ad analizzare l'origine dei dati, infatti, si vede che i parlatori DM e RI sono femmine, mentre MA e MG sono maschi. La struttura 5-LIN ci permetterebbe a priori, cioè senza conoscenze specifiche sul database, di creare una divisione in due gruppi di parlatori. A posteriori si scopre che questi gruppi rappresentano la divisione di sesso tra i parlatore. Nulla vieterebbe di riunire i parlatori più vicini, più confondibili, in un unica LIN.
rappresentino qualcosa che va al di la del semplice riconoscimento di un parlatore, potrebbe anche rappresentare un misura della vicinanza tra i parlatori. Andando ad analizzare l'origine dei dati, infatti, si vede che i parlatori DM e RI sono femmine, mentre MA e MG sono maschi. La struttura 5-LIN ci permetterebbe a priori, cioè senza conoscenze specifiche sul database, di creare una divisione in due gruppi di parlatori. A posteriori si scopre che questi gruppi rappresentano la divisione di sesso tra i parlatore. Nulla vieterebbe di riunire i parlatori più vicini, più confondibili, in un unica LIN.
In questo si otterrebbero delle LIN meno discriminative ma più ''distanti`` tra di loro, quindi con prestazioni migliori come riconoscimento, in questo caso non del parlatore, ma del sesso del parlatore.
La struttura risulta leggermente polarizzata sul parlatore RI, il quale viene riconosciuto in modo migliore (100% in quasi tutti i casi), ma tende a riconoscere per RI anche le frasi del parlatore DM. Questo significa che la rotazione sugli ingressi compiuta da parlatore RI per alcune frasi di DM è migliore. Probabilmente quest'effetto è provocato semplicemente da alcune frasi di test del parlatore DM che sono molto simili a frasi di training del parlatore RI. Questo fatto, unito alla vicinanza tra i due parlatori, con molta probabilità ha provocato la polarizzazione.
Si nota che la rete adattata all'ambiente e la tecnica J-LIN offrono risultati peggiori rispetto alla combinazione LIN+SI. In alcuni casi, infatti, ci sono dei leggeri aumenti delle prestazioni per alcuni parlatori, a discapito di grosse penalizzazioni per gli altri. Per quanto riguarda il peggioramento ottenuto dall'utilizzo di J-LIN anzichè LIN, esso può essere provocato dal minor numero di parametri della struttura J-LIN che riescono a conglobare un minor numero di parametri descrittivi del parlatore.
Le ipotesi fatte sul miglioramento ottenibile utilizzando una rete adattata al canale sono risultate false. La rete adattatata al canale è sicuramente una rete migliore rispetto ad una SI. Le possibili spiegazioni di questo comportamento possono essere attribuite a due fatti:
In questo esperimento si è voluto studiare il variare della percentuale di riconoscimento al variare del numero di frasi utilizzate per il riconoscimento stesso.
Si è addestrata una LIN per ciascuno dei quattro parlatori e sono state caricate in una struttura 5-LIN con una procedura uguale a quella descritta nella sezione (6.1.3).
|
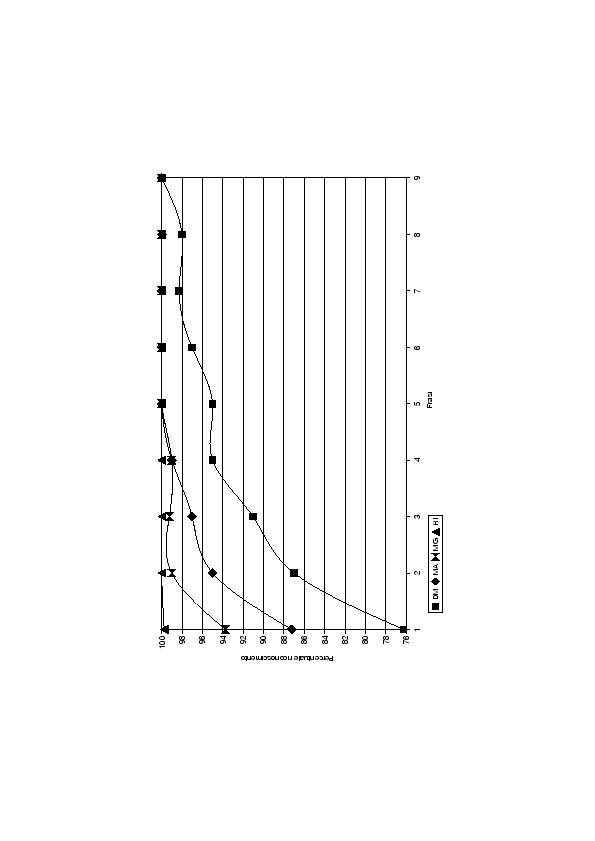
Per ottenere le percentuali di riconoscimento si sono utilizzate diverse quantità di frasi di test: 1, 2, 3, 4, 5, 6, 7, 8, 9 frasi. Avendo 400 frasi di test per ogni parlatore e utilizzando i diversi insiemi, si sono effettuati 400 esperimenti con 1 frase, 200 esperimenti con 2 frasi, fino ad arrivare a 44 esperimenti con 9 frasi.
|
Come nell'esperimento precedente, per ogni parlatore e per ogni insieme di frasi di test si è tenuto traccia del numero di esperimenti assegnati al parlatore DM, MA, MG, RI.
I risultati di questi esperimenti sono riportati in tabella (6.3) e nel grafico (6.5).
Si vede in primo luogo che, all'aumentare del numero di frasi di test, la percentuale di riconoscimento aumenta in maniera decisa per ogni parlatore.
Appare evidente che la LIN del parlatore RI funziona meglio rispetto alle altre: essa, con 2 frasi di test, risponde sempre in modo corretto. I parlatori MA e MG offrono dei risultati tra di loro paragonabili, inferiori rispetto a quelli di RI, ma bastano loro 5 frasi per rispondere con una correttezza del 100%. Anche da questi risultati appare evidente come il modello del parlatore DM sia più debole rispetto al modello degli altri, infatti parte con una percentuale di riconoscimento molto bassa del 76% per arrivare solo dopo 9 frasi a raggiungere il 100%.
Si nota come i grafici (6.5) dei vari parlatori tendano ad avere un comportamento esponenziale: bastano poche frasi per avere un aumento notevole delle prestazioni. Nel caso del parlatore DM con il passaggio da 1 a 2 frasi per il riconoscimento si passa dal 76% al 87%. Questo fa presupporre che solo con un determinato numero di frasi di test i valori dei ![]() riescano a fornire un risultato attendibile, nel caso non abbiano sufficienti frasi per portare il modello in convergenza le prestazioni degenerano rapidamente.
riescano a fornire un risultato attendibile, nel caso non abbiano sufficienti frasi per portare il modello in convergenza le prestazioni degenerano rapidamente.
Per questo esperimento sono state utilizzate delle LIN adattate con 285 frasi per parlatore, un numero molto elevato, non sempre ottenibile nelle applicazioni reali. L'esperimento successivo serve a verificare quanto il modello possa migliorare in funzione del numero di frase di adattamento.
|
|
|
|
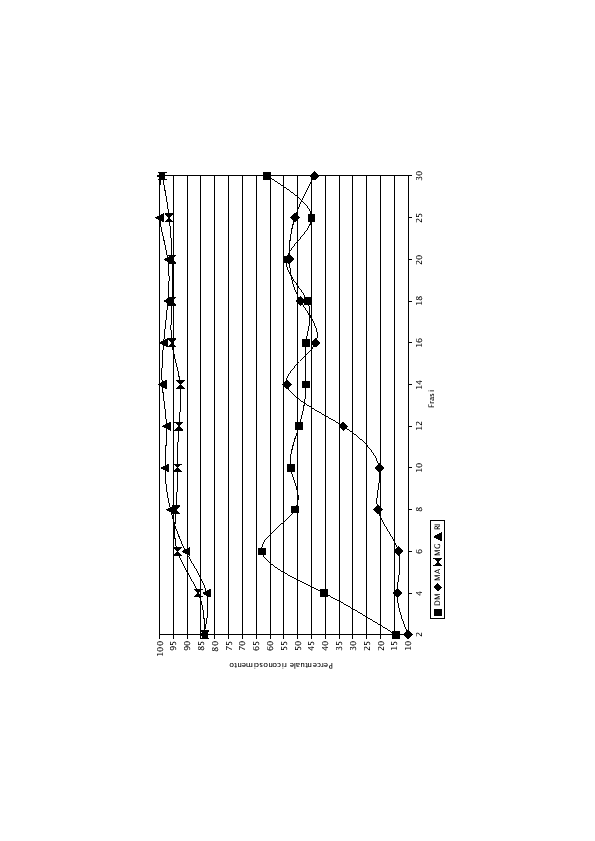
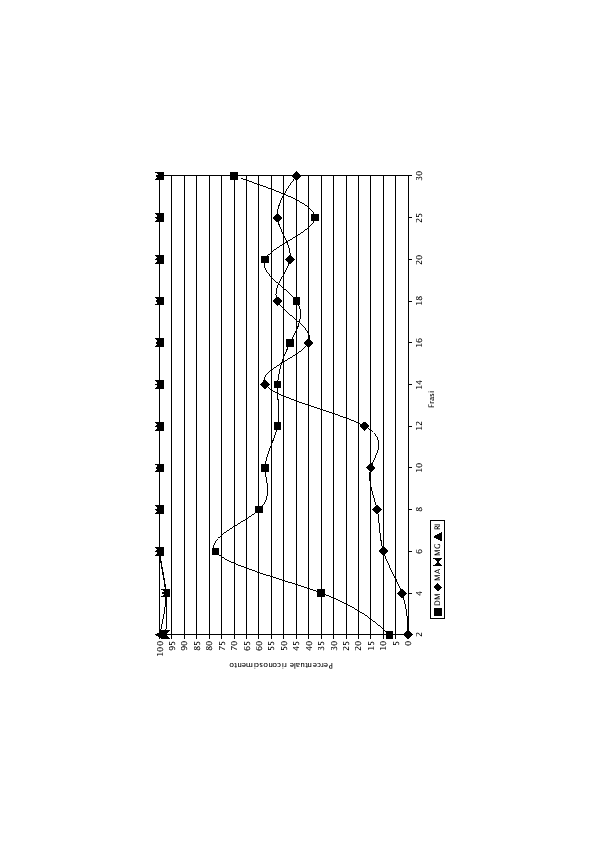
I risultati degli esperimenti sono riportati in tabella (6.4) e nel grafico di figura (6.6) nel caso di gruppi da 2 frasi di test. Il caso con gruppi da 10 frasi di test è invece riportato in tabella (6.5) e in figura (6.7). L'esperimento con gruppi da 10 frasi di test fornisce risultati leggermente migliori rispetto a quello compiuto con 2 frasi, anche se l'andamento dei due grafici è decisamente simile. Si nota come non sempre, all'aumentare del numero di frasi di training, ci sia un corrispondente aumento delle prestazioni.
I grafici mostrano chiaramente come i parlatori DM e MG siano riconosciuti decisamente meglio rispetto a MA e a RI.
Questo comportamento denota semplicemente che, con questo numero di frasi di training, i modelli di DM e di MG rispondono meglio rispetto al modello giusto per quel parlatore. Le quattro LIN non hanno ancora raggiunto una convegenza: con l'aumentare del numero di frasi i modelli di DM e di MG aumentano ancora le loro prestazione e non permettono agli altri due modelli di dare risultati migliori del 50%.
|
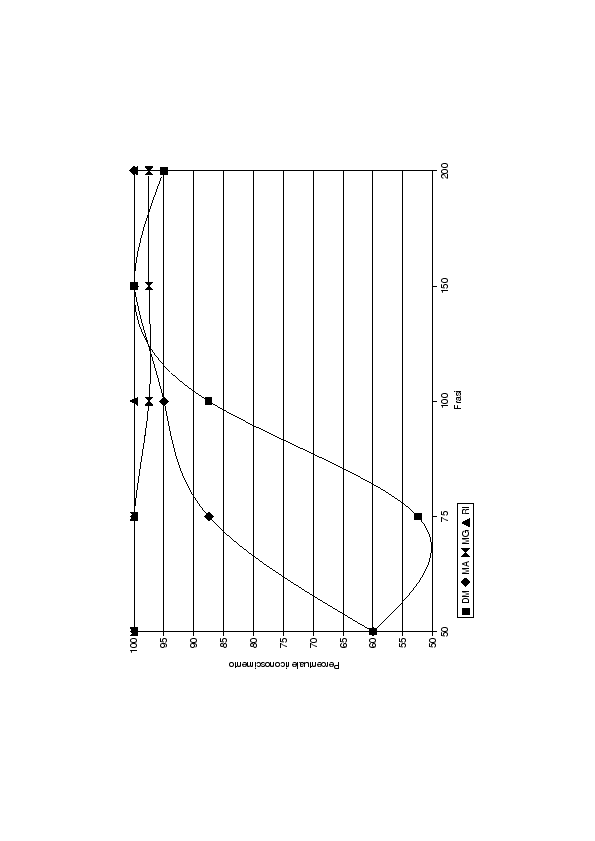
Al fine di individuare con esattezza il punto di convergenza dei quattro modelli si è continuato l'esperimento addestrando le LIN con 50, 75, 100, 150 e 200 frasi di training e utilizzando per il riconoscimento 40 gruppi da 10 frasi di test. Per motivi di spazio sono stati riportati in tabella (6.6) solo i risultati di DM e di MA in quanto i parlatori MG e RI forniscono, con questo numero di frasi di addestramento, un risultato molto vicino al 100%.
|
Come previsto, all'aumentare del numero di frasi di training, tutti i modelli raggiungono la convergenza. I modelli di DM e di MA che prima erano più deboli, iniziano a rispondere meglio rispetto ai modelli di MG ed RI. Dopo 150 frasi di training i risultati sono discreti e nessuno modello ha prestazioni inferiori al 87%. Dopo 200 frasi di training tutti i modelli rispondono praticamente sempre correttamente. Una rappresentazione grafica di questi risultati è data nel grafico di figura (6.8).
Stefano Scanzio 2007-10-16